技嘉GeForceRTX5070TiGAMINGOC16G评测:游戏玩家的致胜选择_技嘉GeForceRTX5070TiGamingOC16G魔鹰_游戏硬件显卡
文章ID:49时间:2025-04-25人气:
随着 5090D/5080的相继发售,市场又掀起了一波抢购热潮。但对于大部分玩家来说RTX 5090D/5080价格相对较高,所以RTX 5070 Ti就成为了更好的选择。随着RTX 5070 Ti的逐步解禁,我们也对技嘉GeForce RTX 5070 Ti GAMING OC 16G显卡进行了深度测试,就让我们一起来看看它究竟能带来怎样的游戏体验?它在散热、功耗控制以及特色功能上又有何独到之处?
此次的技嘉GeForce RTX 5070 Ti GAMING OC 16G在产品包装方面延续了魔鹰系列的一贯风格,将硬核游戏风格和实用美学主义相融合。在包装正面利用显卡、主板等科技数码元素设计了一个大写的字母“G”,让玩家一下就能认出它来自技嘉魔鹰系列。同时在左下角印有GAMING OC 16G字样和风之力散热标识。而右下角则印有GeForce RTX 5070 Ti字样。

回归到技嘉显卡本身,依旧采用了磨砂黑为主的设计。正面导流罩通过不规则的几何线条分割,形成类似装甲板的叠层效果,棱角分明的轮廓搭配斜面折线,营造出机械战甲般的感觉。同时新加入了菱形格装饰,在磨砂黑的衬托下,显卡整体给人一种低调硬朗的质感。




由于这一代的RTX 5070 Ti功耗的增加,所以技嘉也为其配备了全新的风之力散热系统。正面标配了三风扇的布局,并采用仿生叶片,这样的设计灵感来自鹰翅膀的空气动力学,能够有效的降低风阻和噪音,让显卡时刻保持满血状态。同时还具备RGB幻彩灯效。

三个风扇采用逆时针旋转设计,减少了互相之间的气流干扰。同时搭配均热板及服务器级导热凝胶,大大提高散热效率。
背板方面,魔鹰采用了全尺寸金属背板,有效保护PCB的同时,右侧开有大面积的散热风孔,相比上此前的产品,技嘉在这方面做了不小的升级。


接口方面,技嘉GeForce RTX 5070 Ti GAMING OC 16G魔鹰显卡配有1个HDMI 2.1b 接口和3个DP 2.1b接口,保证了高规格的输出能力,可以帮助玩家更好的拓展多屏空间。

GeForce RTX 50系显卡由全新的NVIDIA Blackwell架构打造,本次评测的RTX 5070 Ti采用与RTX 5080相同的GB203核心,配备8960个CUDA,70个RTCores;280个Tensor Cores和280个纹理单元。

而从上图可以看到,RTX 5070 Ti具备1406的AI TOPS;133 RT TFLOPS以及44 Shader TFLOPS算力,以及全新的16GB GDDR7显存。
完整的GB202核心包括12个图形处理集群(GPCs);96个纹理处理集群(TPCs);192个流式多处理器(SMs),和一个512bit总位宽,包含16个32bit内存控制器的内存接口。
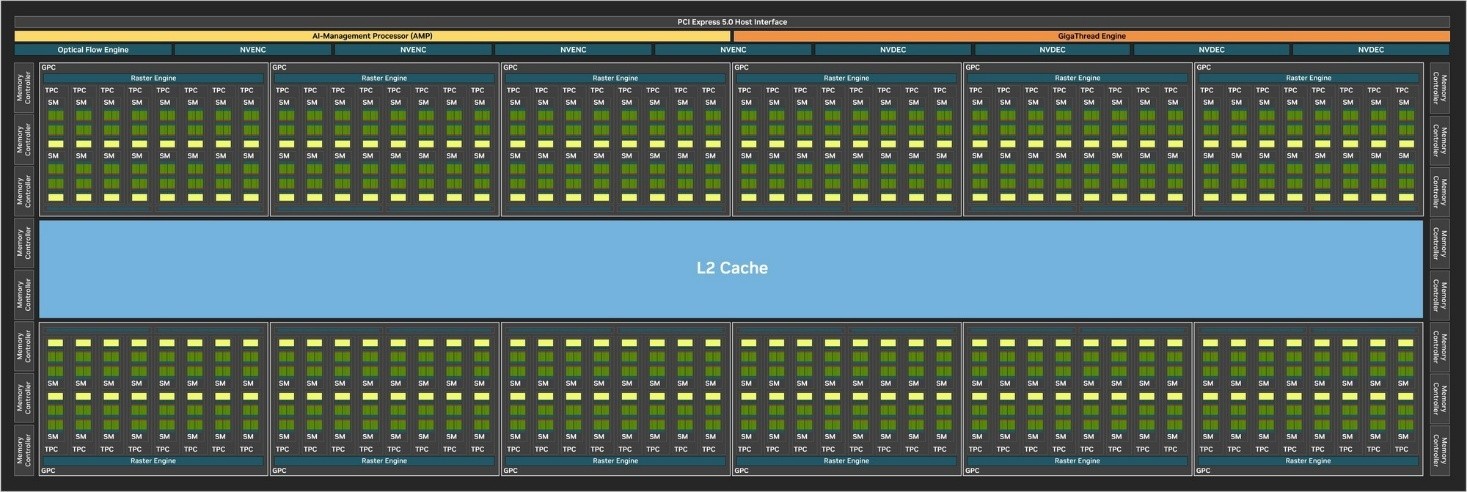
对应到我们熟悉的数字,则是24576个CUDA,192个RT Cores;768个Tensor Cores以及768个纹理单元。由于第5代Tensor Cores采用了更高速的FP4运算,完整的GB202可达到恐怖的4000 AI TOPS;而第4代RT Cores采用的新的几何运算模型,也让它可以达到360 RT TFLOPS。

另外,每个SM单元中还包含两个FP64内核,总共384个。FP64内核主要目的是确保带有FP64代码的程序可正常运行,并确保准其确性。这对于某些专业领域来说至关重要,比如医学或专业计算领域。
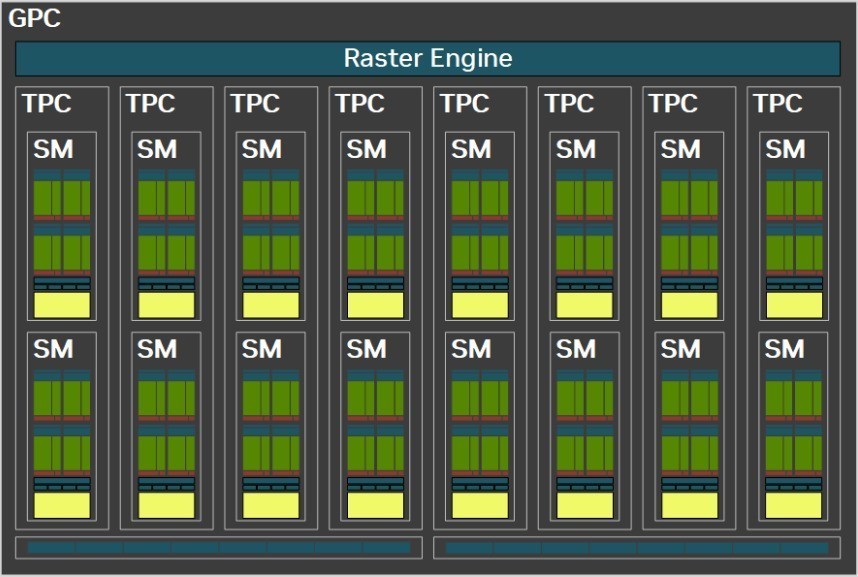
GPC是GPU中占据主导地位的高级模块,所有关键的图形处理单元都位于GPC中。在RTX 50系中,GPC整体的布局变化不大。
每个GPC包含一个专用的光栅引擎,两个ROP分区。每个分区包含8个单独的ROP单元和8个TPC,每个TPC包含1个变形引擎和两个SM单元。
完整的GB202核心还包含128MB的L2缓存。大缓存的变更自RTX 40系显卡便已开始,所有程序都可以受益于这个高速大容量的缓存池,而光线跟踪(特别是路径跟踪)等复杂操作将产生巨大的好处。
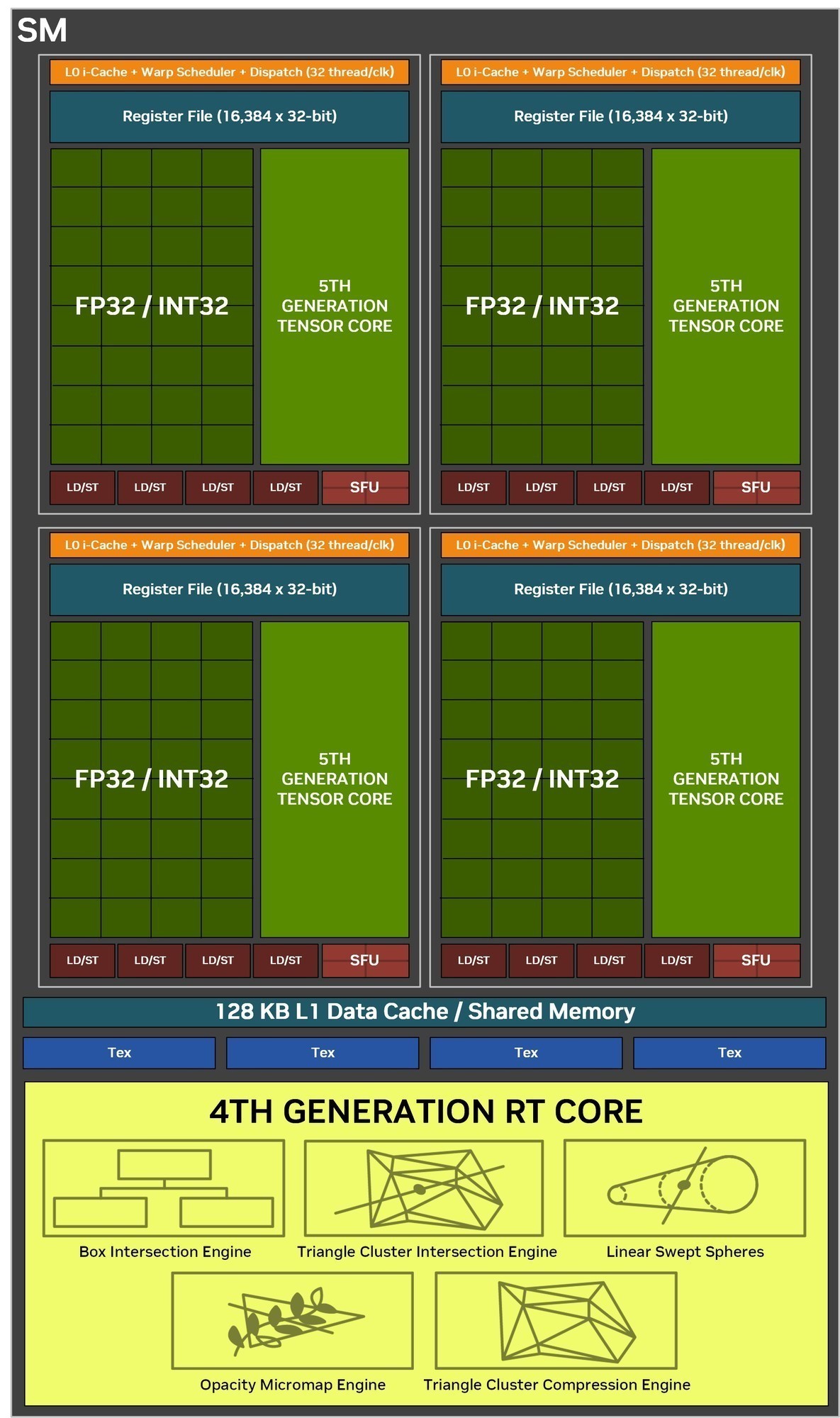
SM单元是GPU架构中的核心组件,在GPU并行处理中发挥着关键作用,它通过其各种核心(CUDA,Tensor,RT),高效的warp调度,内存管理以及对AI等现代工作负载的支持实现大规模并行。本代RTX 50系显卡中SM单元的变化非常大,下面我们详细来了解一下。
完整的GB202核心包含192个SM单元,每个SM包含128个CUDA核心;1个第4代RT Core;4个第5代Tensor Core;4个纹理单元。1个256KB的寄存器文件和128KB的L1共享缓存,它可以根据图形和计算工作负载的需要配置不同的大小。
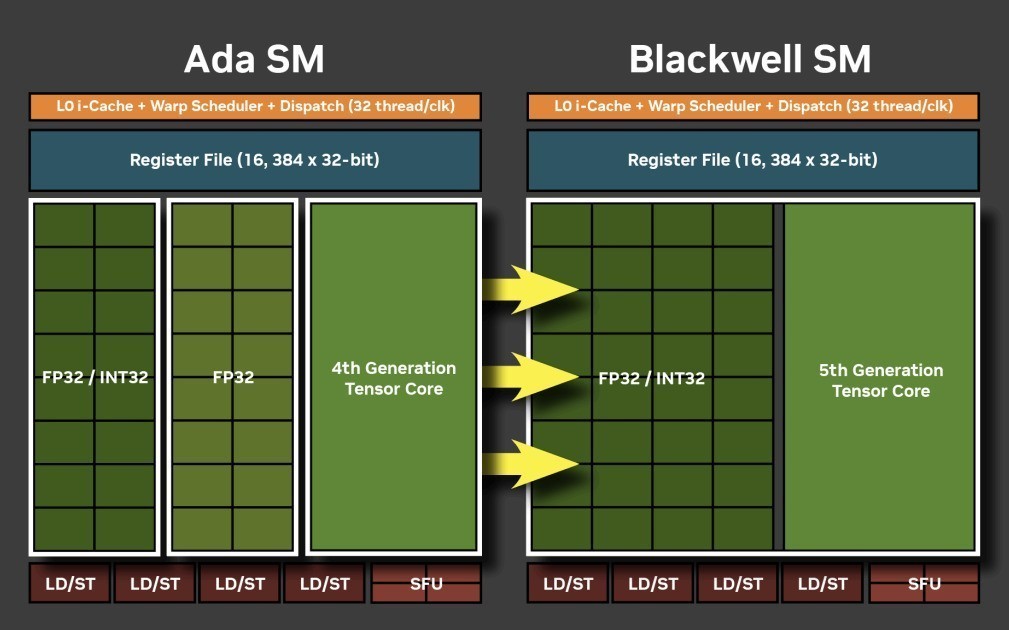
在Blackwell架构的SM单元中,INT32整数运算的数量增加了一倍。与Ada架构的SM单元相比,实现了INT32与FP32内核的完全统一。不过在时钟周期内,统一内核只能作为FP32或INT32内核运行。
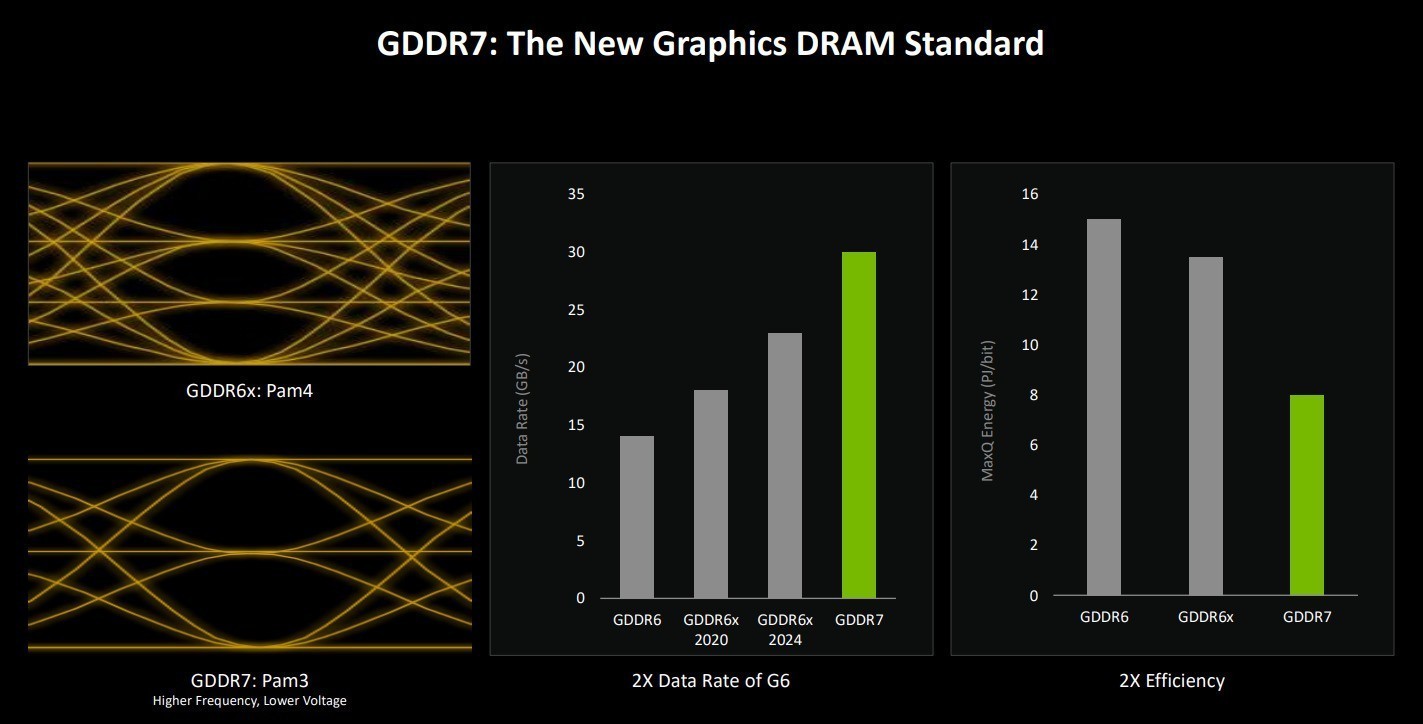
与Blackwell架构一同推出的还有GDDR7显存,采用pam3信号技术,它有着更高频率与更低电压的特点。
本代RTX 5070 Ti配备28Gbps GDDR7显存,峰值显存带宽可达1792GB/s/秒,而RTX 5080配备更高的30Gbps时钟频率的GDDR7显存,峰值内存带宽可达960GB/秒。结合新的引脚编码方案,GDDR7实现了显著增强的信噪比(SNR)。
通过增加信道密度、改进的pam3信噪比、先进的均衡方案、重新设计的时钟架构和增强的I/O训练,GDDR7提供了更高的带宽。这些进步还显著提高了能源效率,提供了更好的性能和延长电池寿命,特别是在移动端,或功率受限的系统中。
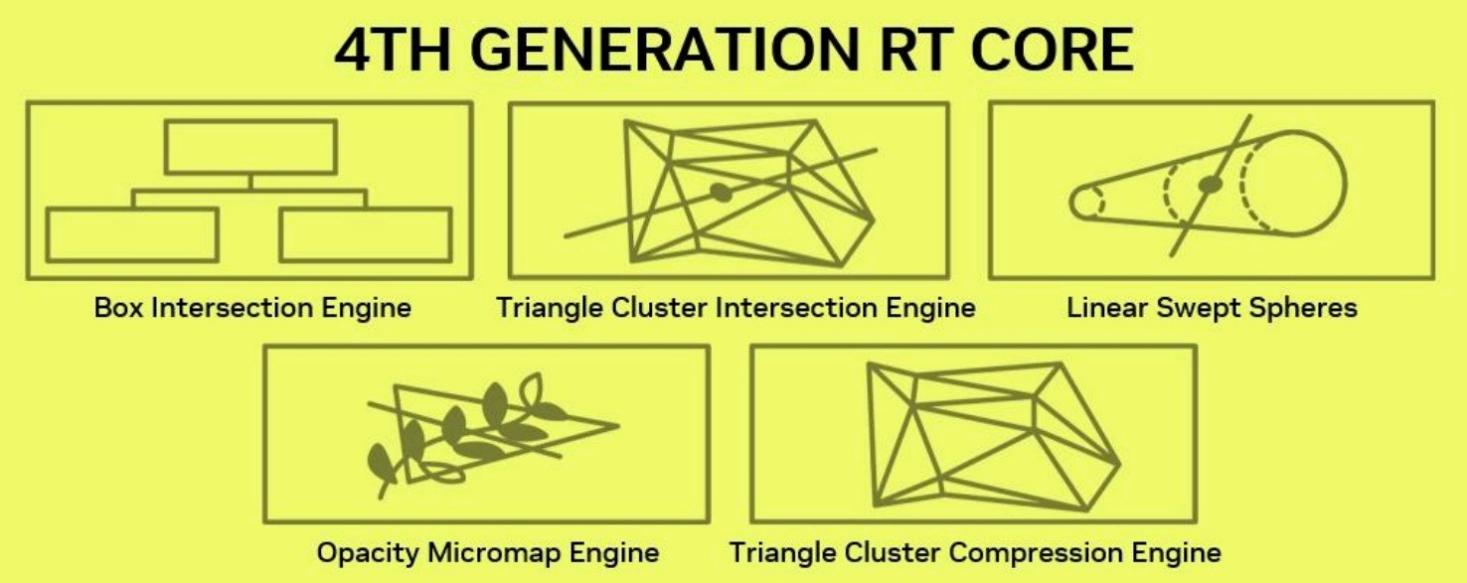
在第4代RT Core中,简单来说它相比Ada架构,在渲染光线追踪场景时,提供了两倍光线三角形相交测试吞吐量,并引入了Mega Geometry的结构算法。
不透明微引擎在Ada架构中已经引入,这里不再过多讲述,它主要的作用是优化光线追踪渲染,可大幅减轻着色器的工作负担。
比如树叶之类的复杂物体,不同的光线都会影响它的表现状态,以及树叶之间的光线反弹,所以对于光线追踪的计算量是巨大的。
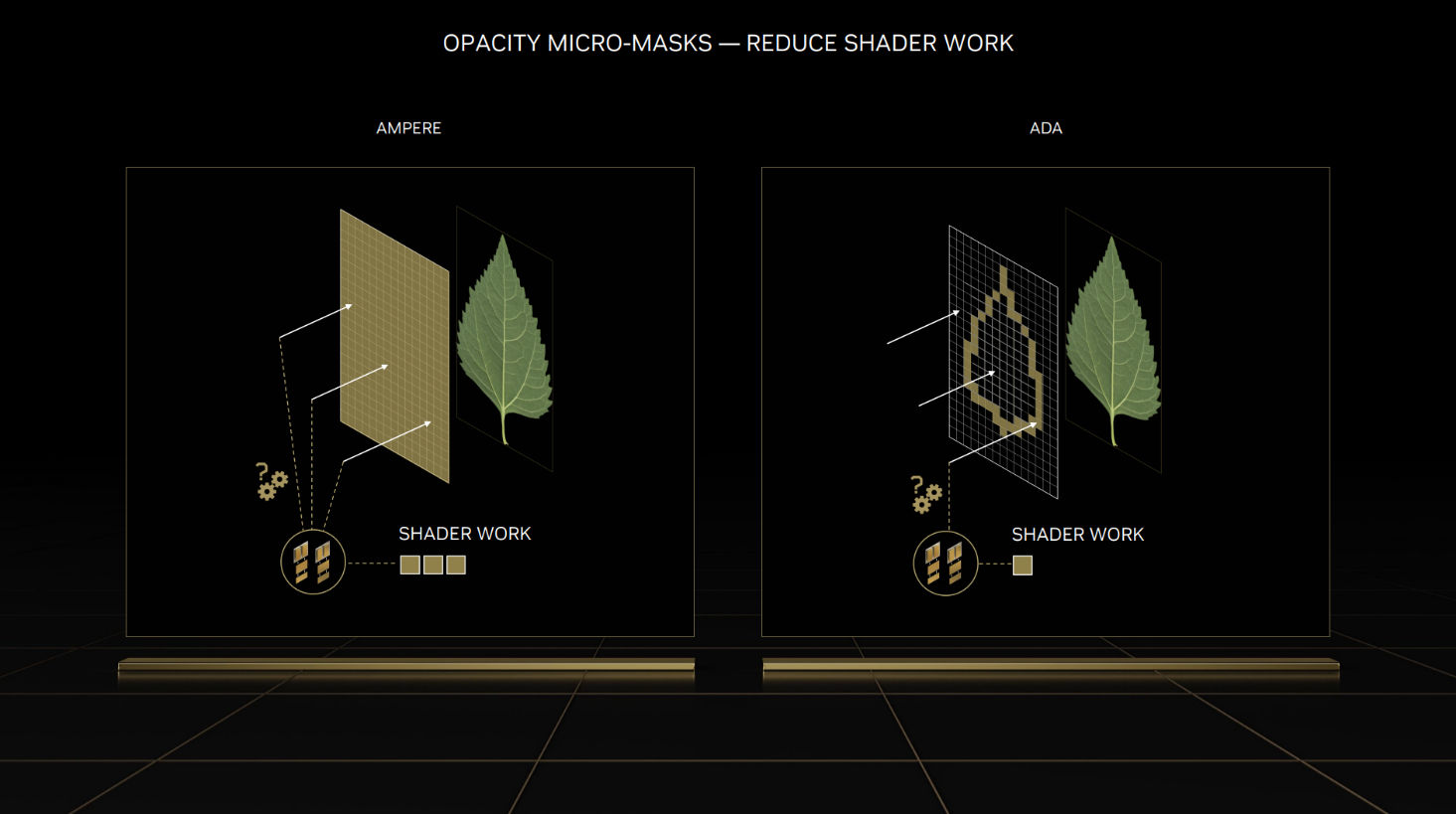
不过Opacity Micromap Engine可以将光线追踪特性烘焙到不透明蒙版中,所以那些不规则形状和半透明的对象,也就能够更快更精准的渲染出来,从而极大减轻着色器的工作负担。
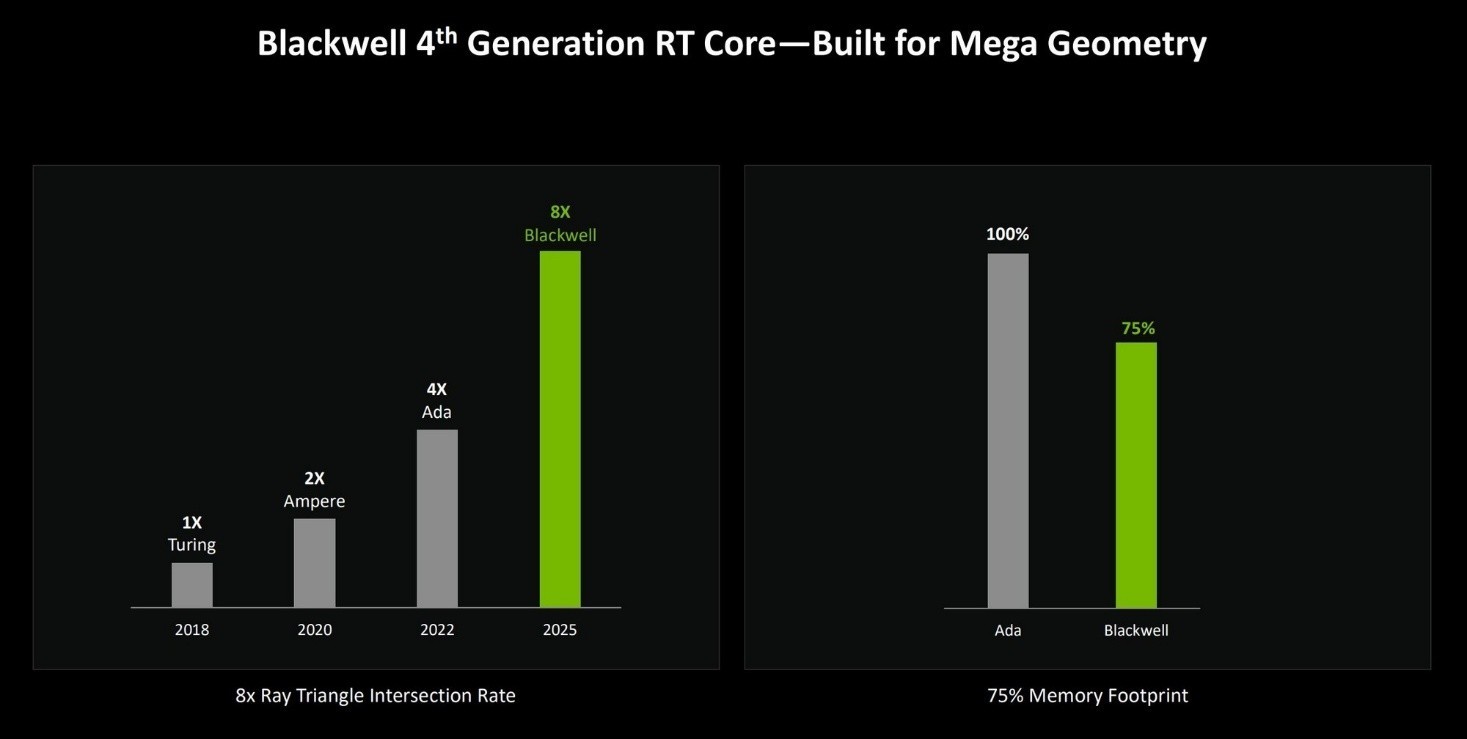
除了上面提到的Opacity Micromap Engine,在BlackWell架构中,还引入了Mega Geometry(大型几何)的运算概念。其中包含了Triangle ClusterIntersection Engine、Linear Swept Spheres等新硬件。

新的Blackwell RT核心包含一个Triangle ClusterIntersection Engine三角形群集交集引擎,它能够进一步加速大型几何的光线追踪,同时它的工作还包含标准的光线三角形交集测试。Linear Swept Spheres则主要用于光线追踪中精细的几何形状,比如发丝。
RTX Mega Geometry的理念与虚幻5引擎的Nanite虚拟微多边形几何体系统相同,在现代游戏中,模型更加细致,需要渲染的工作量大幅增加,如果全部按照最精细的级别处理,将会耗费极大的计算资源,所以将LOD分级便应运而生。
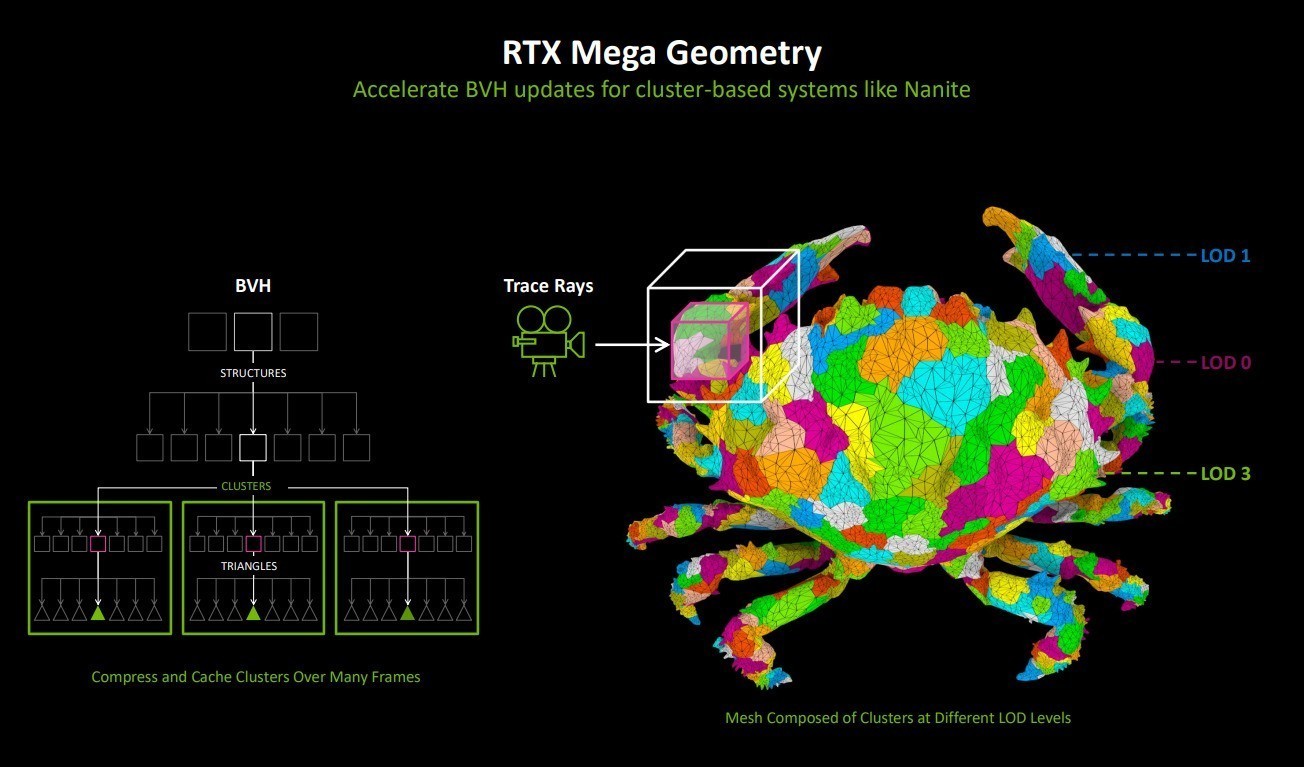
简单来说,就是根据一个物体距离摄像机的远近,来调节物体的细节水平。此前《黑神话:悟空》便应用了这样的技术,它消除了LOD的繁琐任务,可以扫描并导入极高精细程度的模型。并且,这不会影响性能。仍然可以获得实时帧速率。
在RTX Mega Geometry中提供了新的BVH构建功能,它采用三角形集群作为一级基元。新的集群加速结构Cluster-level Acceleration Structures(CLAS)可以从256个三角形空间紧凑批次中生成,然后使用CLAS集合作为输入来构建最终的BVH。
不过虚幻5引擎并非专为Blackwell而设计,RTX Mega Geometry的工作只是更高效的让游戏引擎调用API。由于其输入参数完全由GPU内存,游戏引擎可以在GPU上更高效的运行LOD选择、动画、剔除等逻辑。同时最大限度减少对CPU的往返,进而减少与BVH管理相关的CPU开销。
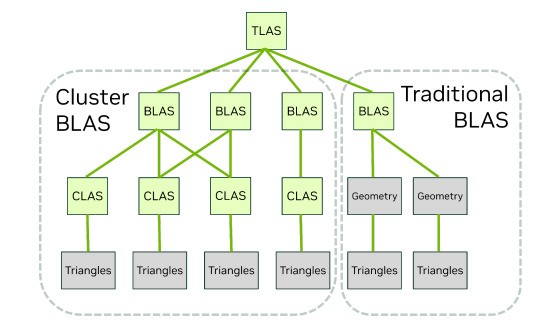
然而在更加精细化的游戏引擎中,按照传统的流程,应用程序必须从场景中的每一帧的所有对象中构建一个顶层加速结构。而随着更大的世界规模以及繁杂的场景物体,仅靠LOD分级仍然难以实现质的变化。
为了解决这个问题,RTX Mega Geometry引入了一种新型的顶层加速结构(TLAS),称为分区顶层加速结构(PTLAS)。
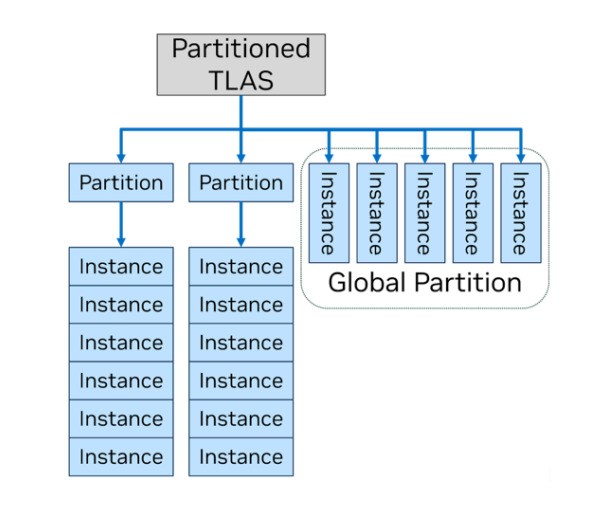
它无需在每一帧都从头开始构建一个新的TLAS,PTLAS能够辨别从一帧到另一帧,哪些对象是静态的。
应用程序通过将对象聚合到分区中,并仅更新那些已更改的对象来节省开销。

例如,游戏可以将静态游戏世界的各个部分放入所属的分区中,同时将动态对象分离到每帧重建的“全局分区”中。与传统的TLAS相比,请求的分区更新越少,节省的运行时开销就越大。
另外好消息是,RTX Mega Geometry可通过底层API进行扩展支持,适用于所有支持光线追踪的NVIDIA GPU,也就是从图灵架构(Turing)开始。
不过Blackwell的第4代RTCore是专门为RTX Mega Geometry而设计的,硬件中的特殊集群引擎实现了几何和BVH数据的新方案,同时是第3代RTCore光线三角形相交率的2倍。因此,Blackwell架构可以实现用更小的显存,更高效的处理这些内容。
LSS(线性扫描球体)是Blackwell架构中新增的图形语言,它极大地简化了复杂头发和毛发的渲染开销,并能提升质量。
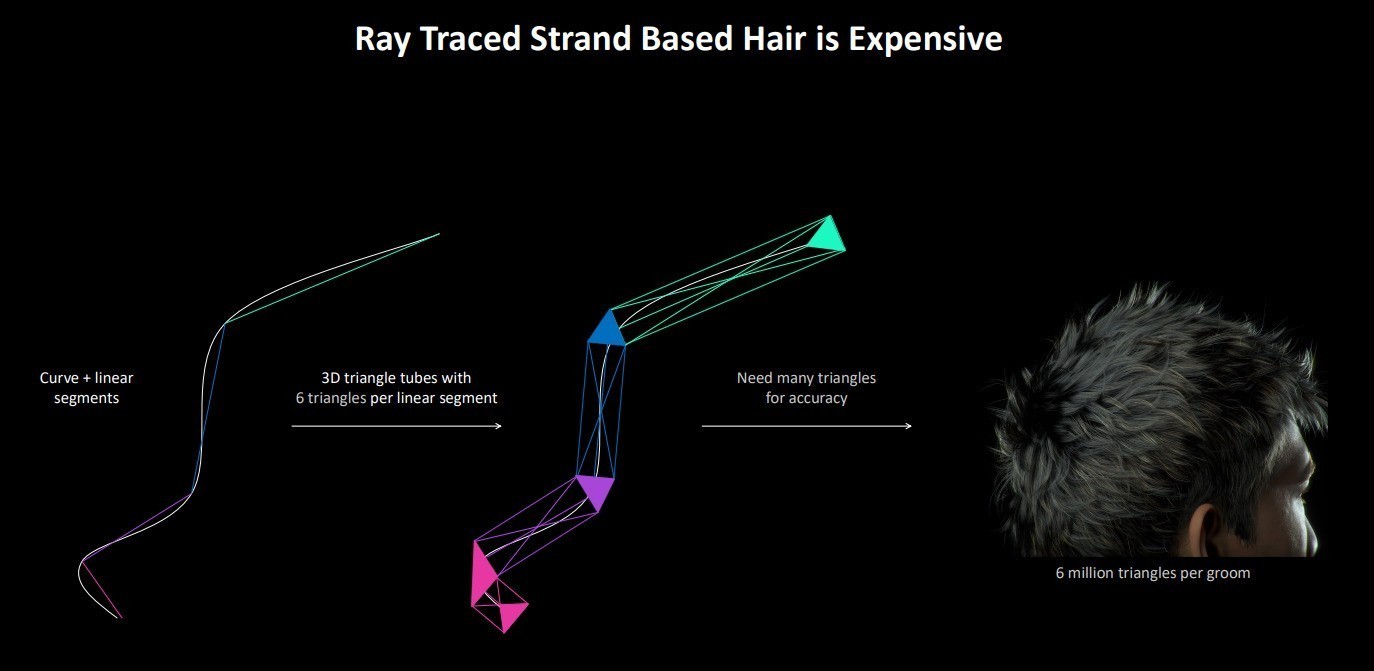
此前渲染头发仍然需要最基础的三角形来表达物体,如图所示,发丝中的一个线段需要6个三角形,而一根头发便需要无数个三角形来确保其精度。比如我们的头发则需要600万个三角形来表达。
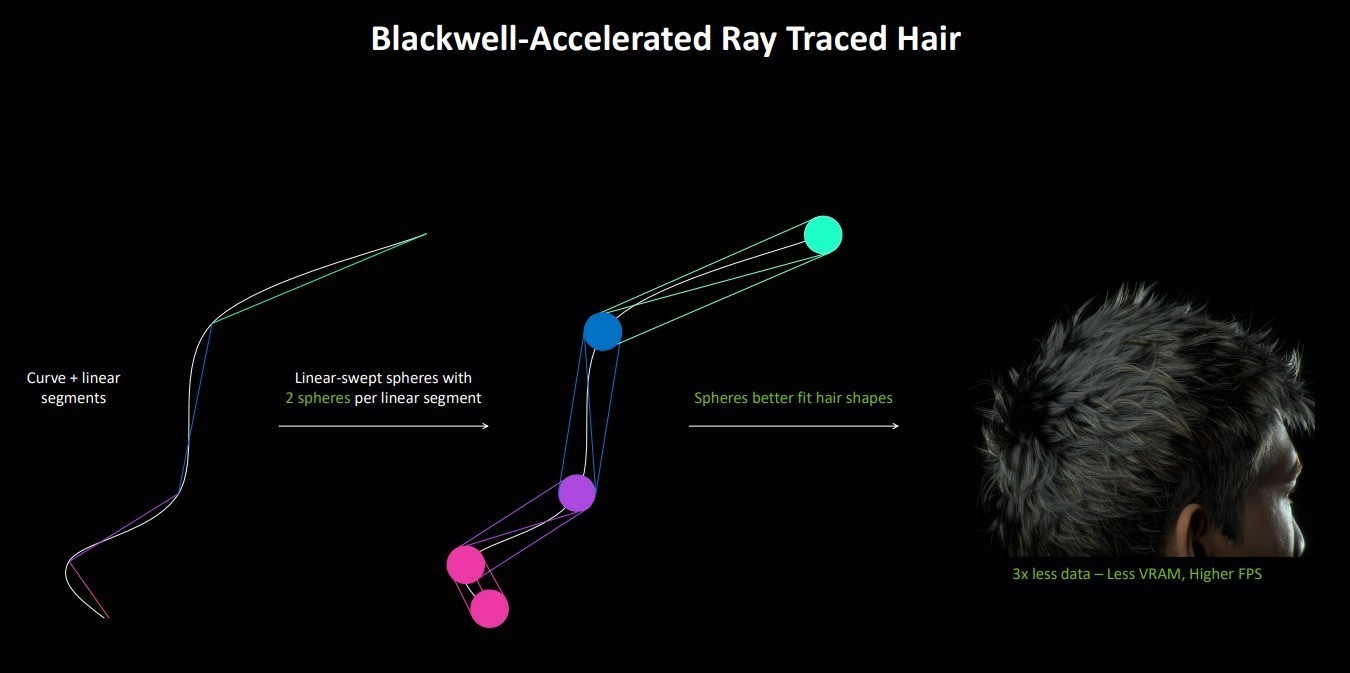
Blackwell架构的RT Core引入了LSS新语言的支持,它类似于镶嵌曲线,允许灵活地近似各种链型。并且球体也更适合发行构建。
LSS的引入可以让发型构建,减少3倍的数据量,速度大约快了2倍,并可以使用更少的显存,获得更高的帧数。
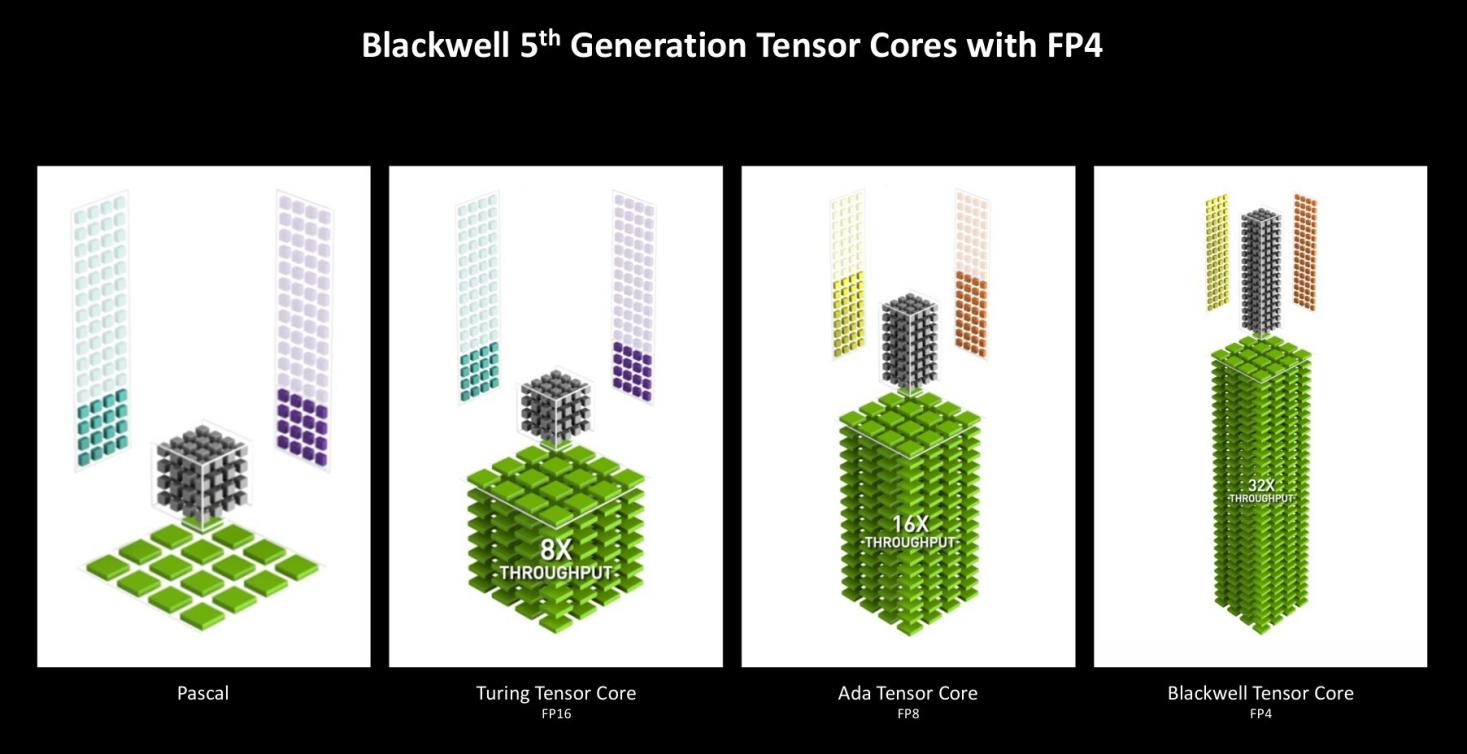
本代架构除了RT Core进行了改进升级,专门负责AI及高性能计算的Tensor Core也迎来了重大升级。
与NVIDIA Ada Tensor Cores一样,Blackwell架构的Tensor Cores支持FP16、BF16、TF32、INT8、INT4和Hopper的FP8Transformer Engine。
Blackwell还增加了对FP4和FP6 Tensor Core操作的新支持,以及新的第二代FP8 Transformer Engine。
FP4提供了一种较低的量化方法,类似于文件压缩,可以减小模型大小,提升生成速度。与FP16精度(大多数型号发布的默认方法)相比,FP4只需要不到一半的显存。FP4使用NVIDIA TensorRT提供的量化方法,几乎没有质量损失。

例如,目前最强的AI绘画模型FLUX.dev,在FP16上需要超过23GB的显存,而这意味着它只能由每一代的期间产品RTX 4090,RTX 5090和专业GPU来支持。
而对于FP4,FLUX.dev测试对显存的需求将少于10GB,让更多80级和70级的显卡均能在本地运行。
在性能和效果对比上,使用带有FP16的RTX 4090,FLUX.dev模型可以通过30个步骤在15秒内生成图像。使用带有FP4的RTX 5090,只需5秒多一点就可以生成图像。
DLSS4是本代RTX 50系显卡带来的重大更新,对于玩家来说它也是最能实际感受到的。最新版本DLSS4带来了新的多帧生成(MFG),具有更快的性能和更低的显存使用等特性。包含超分辨率(SR),光线重建(RR)和深度学习抗锯齿(DLAA)模型,可进一步增强图像质量和稳定性。
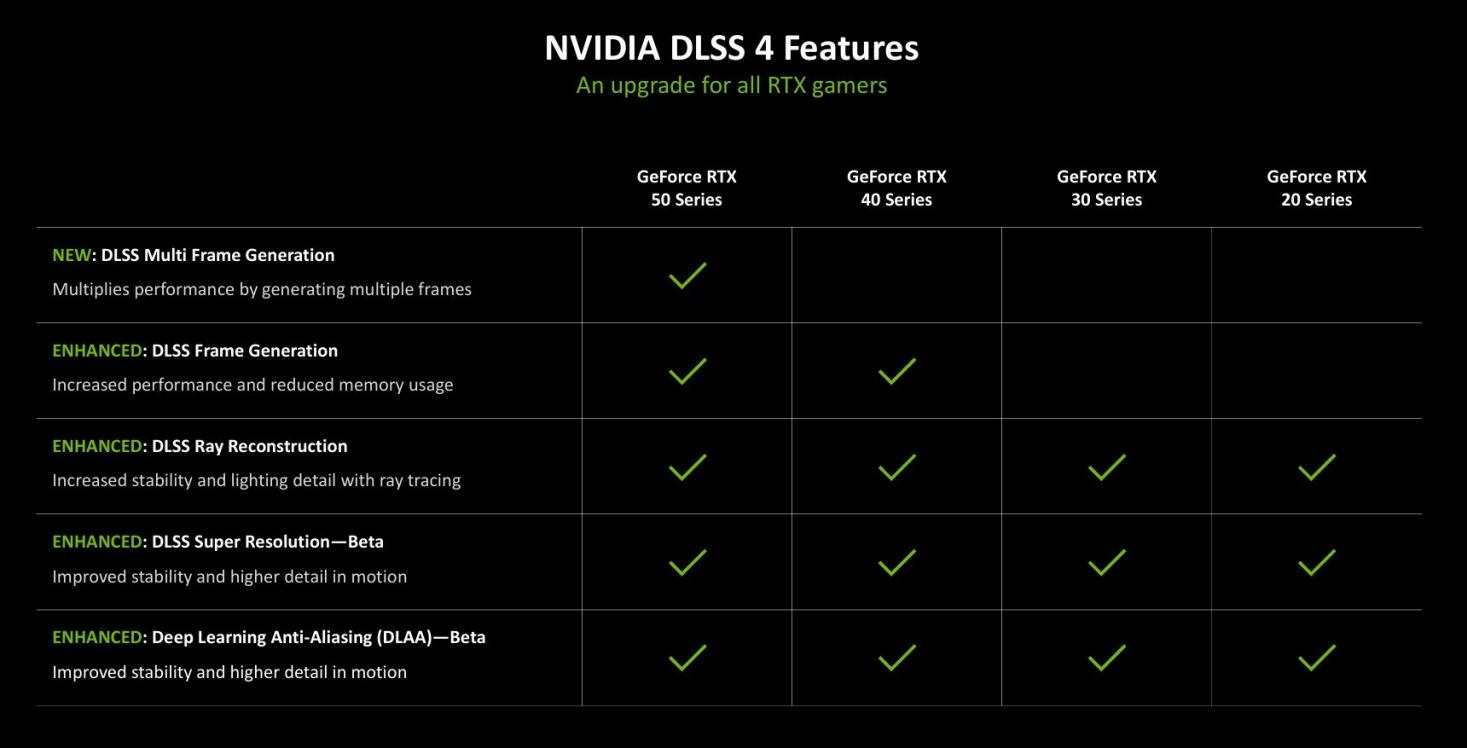
这些新技术由RTX50系GPU和第5代Tensor Cores支持,并由云端的NVIDIA Al超级计算机提供支持。不过对于手持RTX40系或更早期显卡的玩家还无缘体会。DLSS4新增的多帧生成,目前仅支持RTX50系显卡。
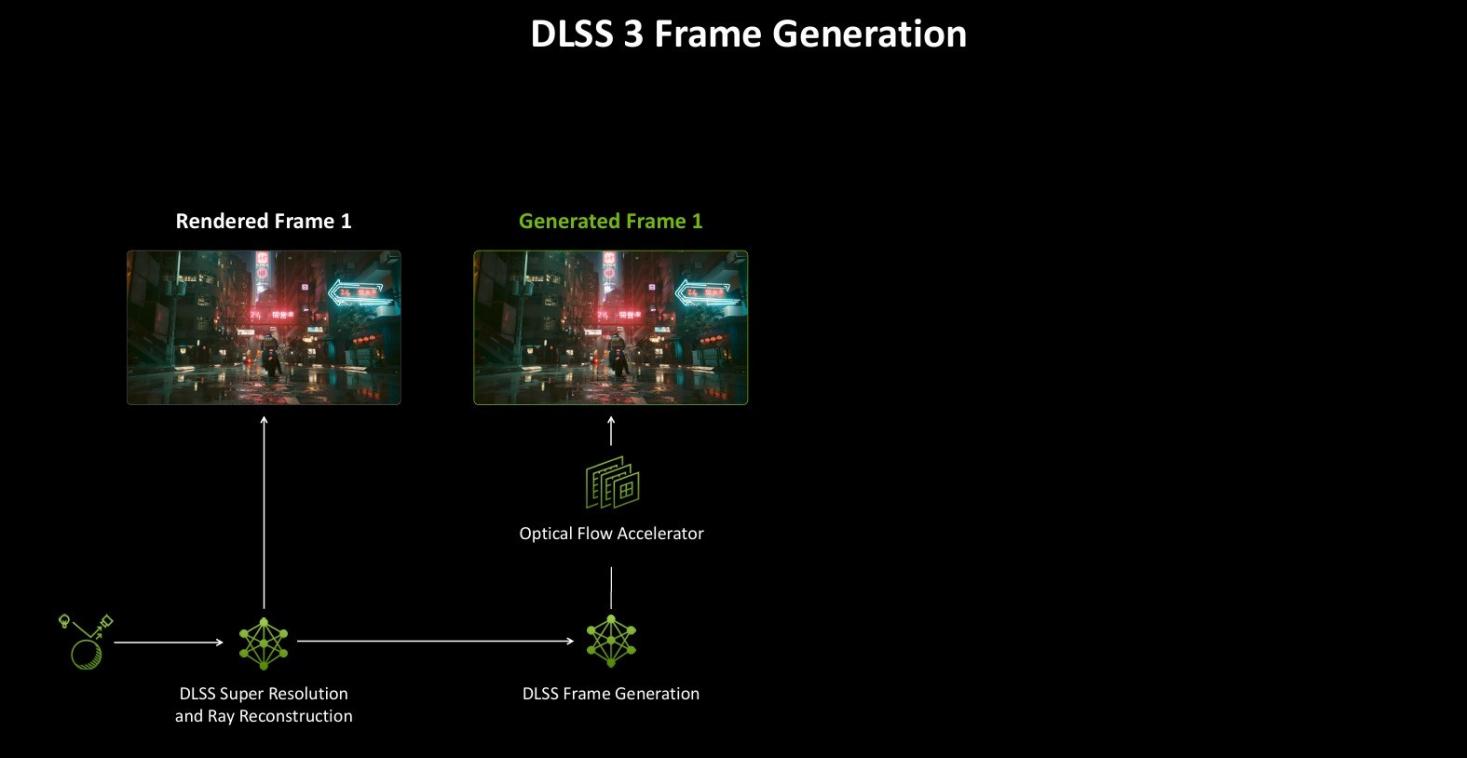
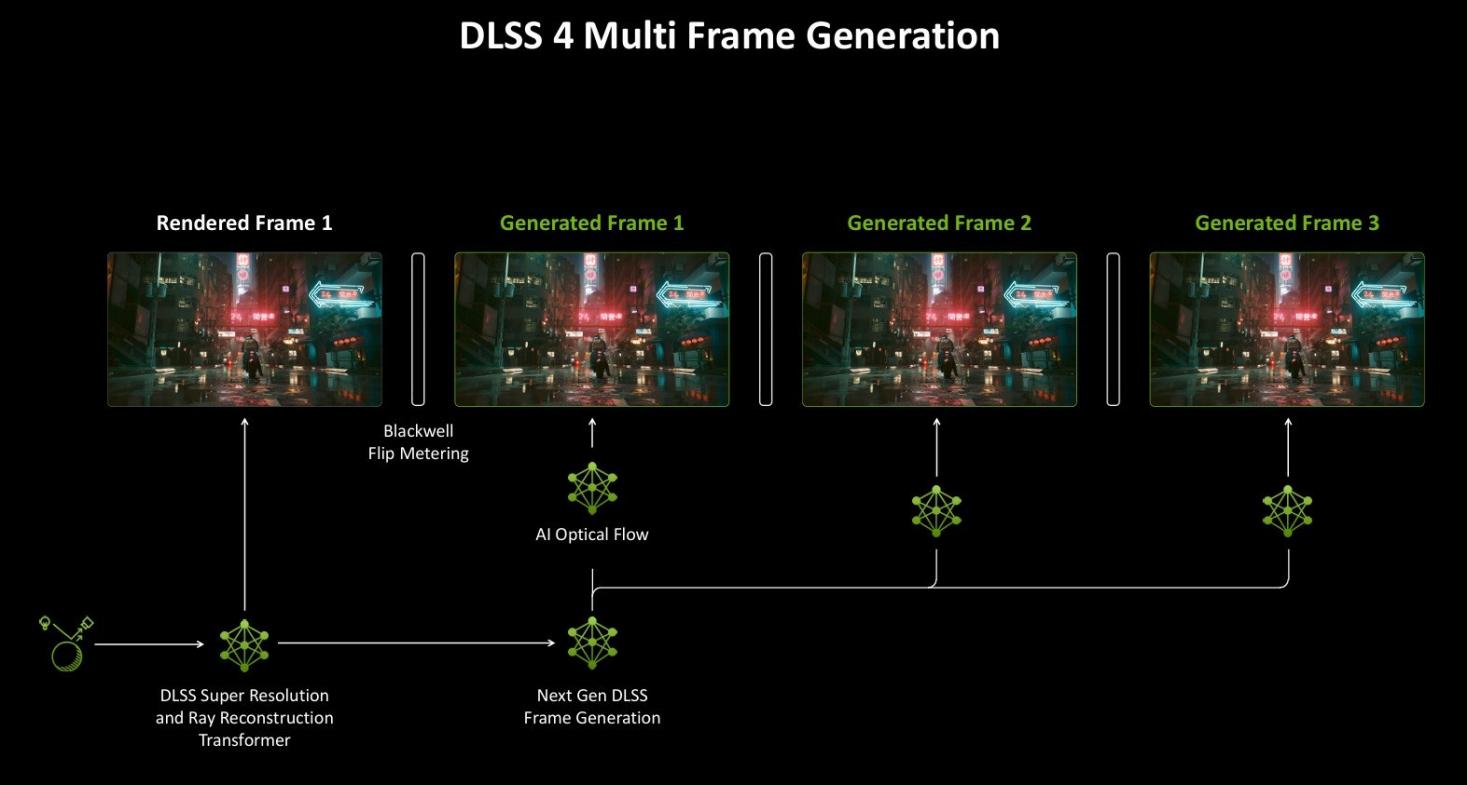
为了解决生成多帧的复杂性,Blackwell架构将帧节奏逻辑转移到显示引擎,使GPU能够更精确地管理显示时序,从而避免与额外帧混合的情况,进而提升帧生成的准确性及稳定性。

而第5代Tensor Cores拥有更高的计算能力,这使得它们能够更快地执行计算光流和生成多帧的一系列AI模型。并更好地调度DLSSAI处理、图形渲染和帧速度算法。
此前DLSS所用的模型为Convolutional Neural Network,即我们熟悉的卷积神经网络(CNN),CNN的工作原理是将像素局部聚集在一起,并以树的形式从低到高地进行分析数据。这种结构的计算效率很高,这也是为什么它被称为卷积神经网络。

而DLSS4引入了基于Transformer的AI模型,用于DLSS超分辨率、DLSS光线重建和深度学习抗锯齿(DLAA),从而提高图像质量和渲染平滑度。基于Transformer模型体系结构的神经网络,擅长处理涉及顺序和结构化数据的任务。简单来说,就是Transformer能够抓住“重点”,可以更好地理解和渲染复杂场景。
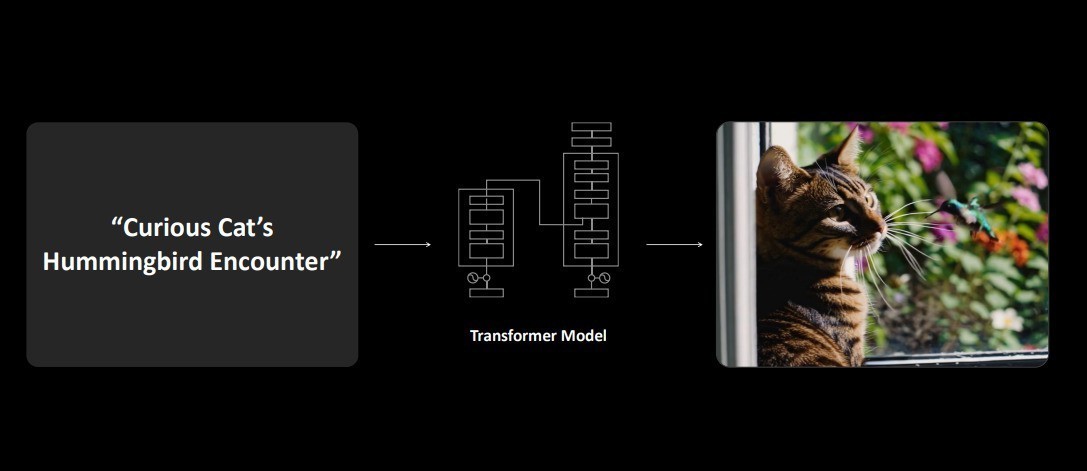
与CNN模型相比,Transformer更容易在更大的像素窗口中识别更远距离的模式,具有一定的学习能力和“前瞻性”。
本代DLSS4将基于CNN的神经网络结构,转变为基于Transformer的神经网络结构,在许多场景下图像质量都有着显著提升。
Shader Execution Reordering(着色器重排序)是在RTX 40系架构中引入的一项技术,它可以使带有光追的程序有效地重组GPU上的大量并行线程,以最大限度地利用硬件。
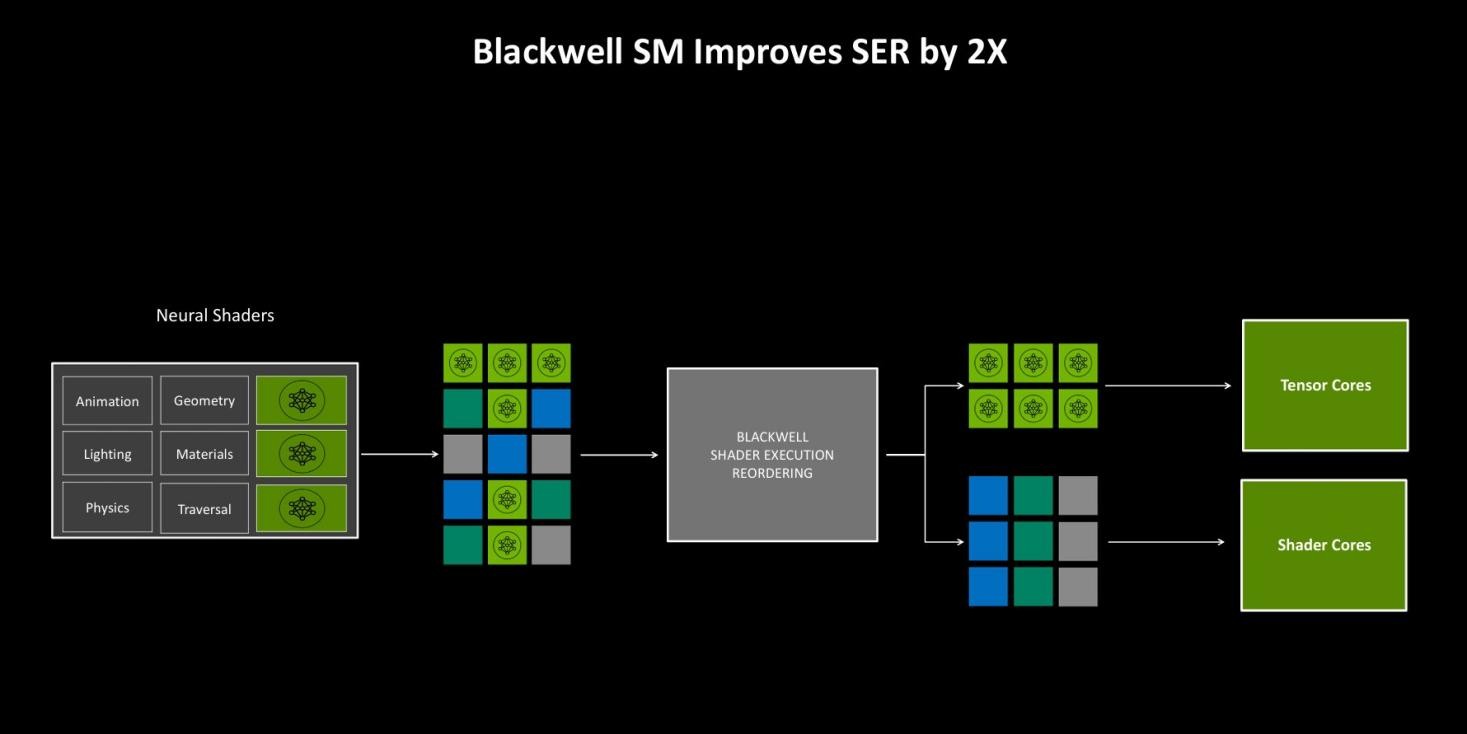
因为连贯执行神经工作负载的线程可以直接发送到Tensor Core,所以SER也显著加速了神经着色。在Blackwell架构中,SER的核心重排序逻辑效率是原来的两倍,减少了重排序开销并提高了精度。从而进一步提高了该功能的有效性。这项功能更多地是为应用程序开发者而设计,它仅需一个小的API改动,即可执行重排序操作,进而提升总体项目的负载性能。
首先介绍一下测试平台,为了保障RTX 5070 Ti 1的性能发挥,我们的平台也再次进行了全面更新。

除了RTX 5070 Ti 16GB这张显卡,处理器选择了 R7 9800X3D游戏神U。内存为32GB DDR5 6400MHz,系统版本为24H2。
为了方便观察DLSS4在画质上的提升和4K高帧率带来的游戏变化。我们选择了EVNIA 32M2N8800 OLED显示器,这款显示器采用了4K@240Hz的高分高刷规格,可完美适配DLSS4的多帧生成。而99%的DCI-P3色域覆盖,更可细致入微地观察Transformer模型带来的细节提升。
本次RTX 50系显卡采用了带宽速率更高的PCIe5.0x16,应用于显卡的PCIe 5.0x16带宽速度高达128GB/s,用于固态硬盘的PCIe 5.0x4也高达32GB/s,致态TiPro9000,实测顺序读写速度高达14526.95MB/s和13869.24MB/s,达到“满血”级别,可大幅提升操作系统/大型游戏/创作的响应和加载速度。
电源选择了昆仑九重KE-1300P,它拥有独到的数字电源技术,在实现1300W满火力输出的同时,更有着超越白金牌的效率表现,成为高端攒机的理想之选。
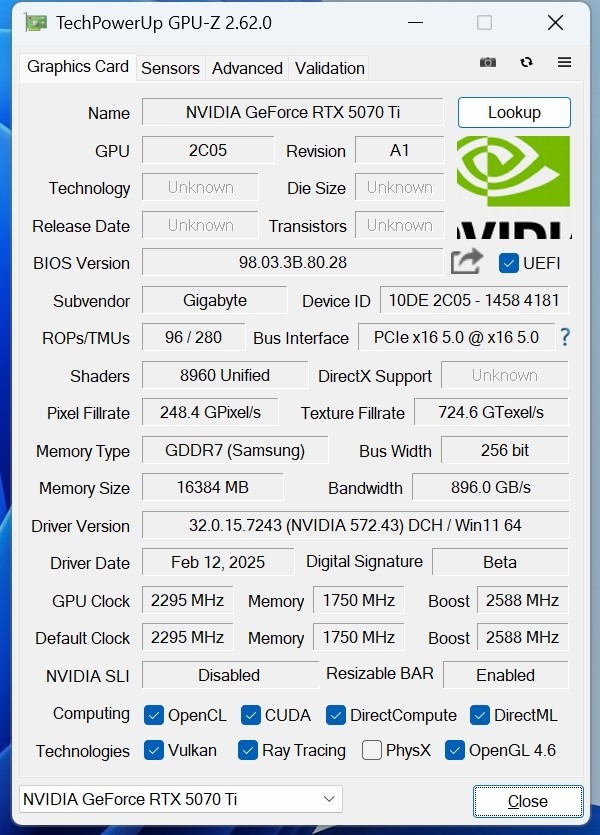
显卡拥有8960个CUDA,Boost频率达到了2588MHz。采用16GBGDDR7显存,位宽为256bit,显存带宽达到了896GB/s,光栅单元和纹理单元为96/280。
下面先进行的是用来衡量显卡理论性能的 FS套装:FS,FSE,FSU三者分别对应显卡在1080P、2K、4K的理论性能,取显卡分数实际测试结果如下:
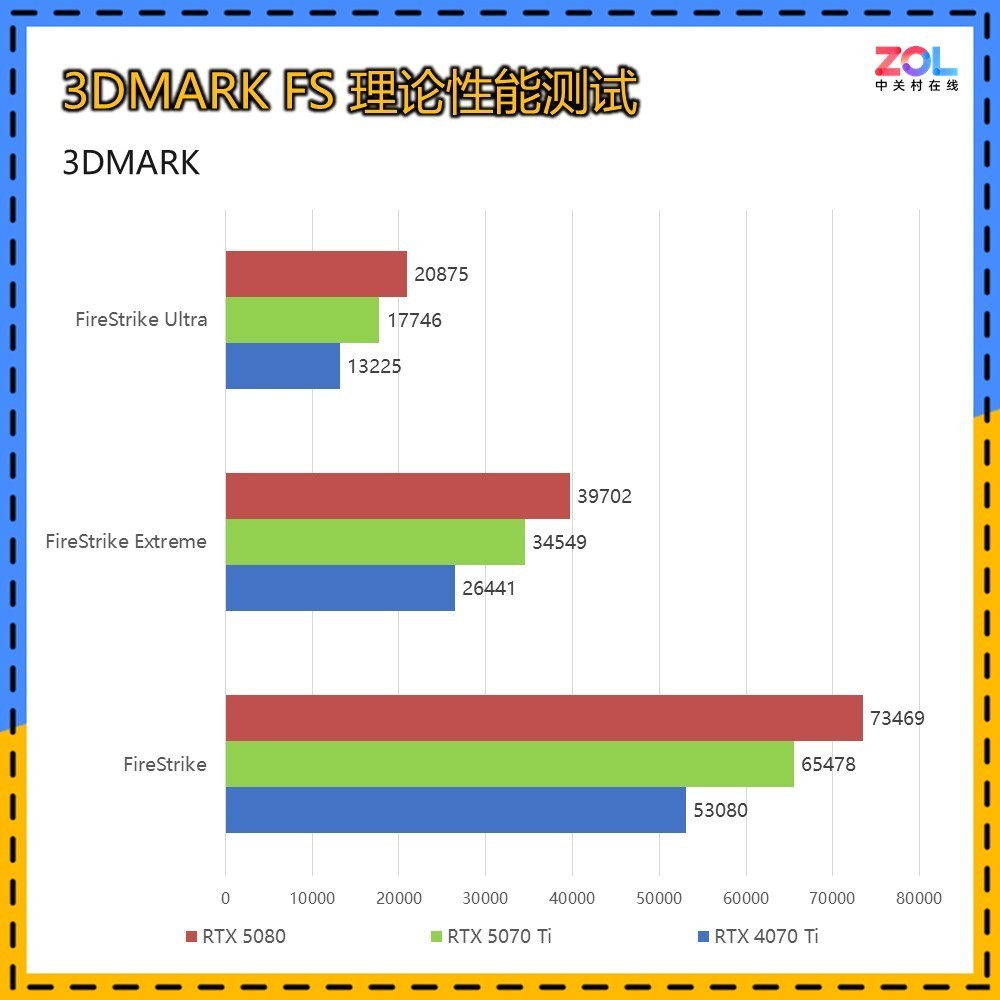
在针对显卡DX11性能的3DMARK FS套装测试中,RTX 5070 Ti 16GB的提升对比RTX 5080,和RTX 4070 Ti,在三档分辨率中相较RTX 4070 Ti提升分别为,23%/31%/34%,综合提升约为29%。而相比RTX 5080的差距为11%/13%/15%,综合约为13%。
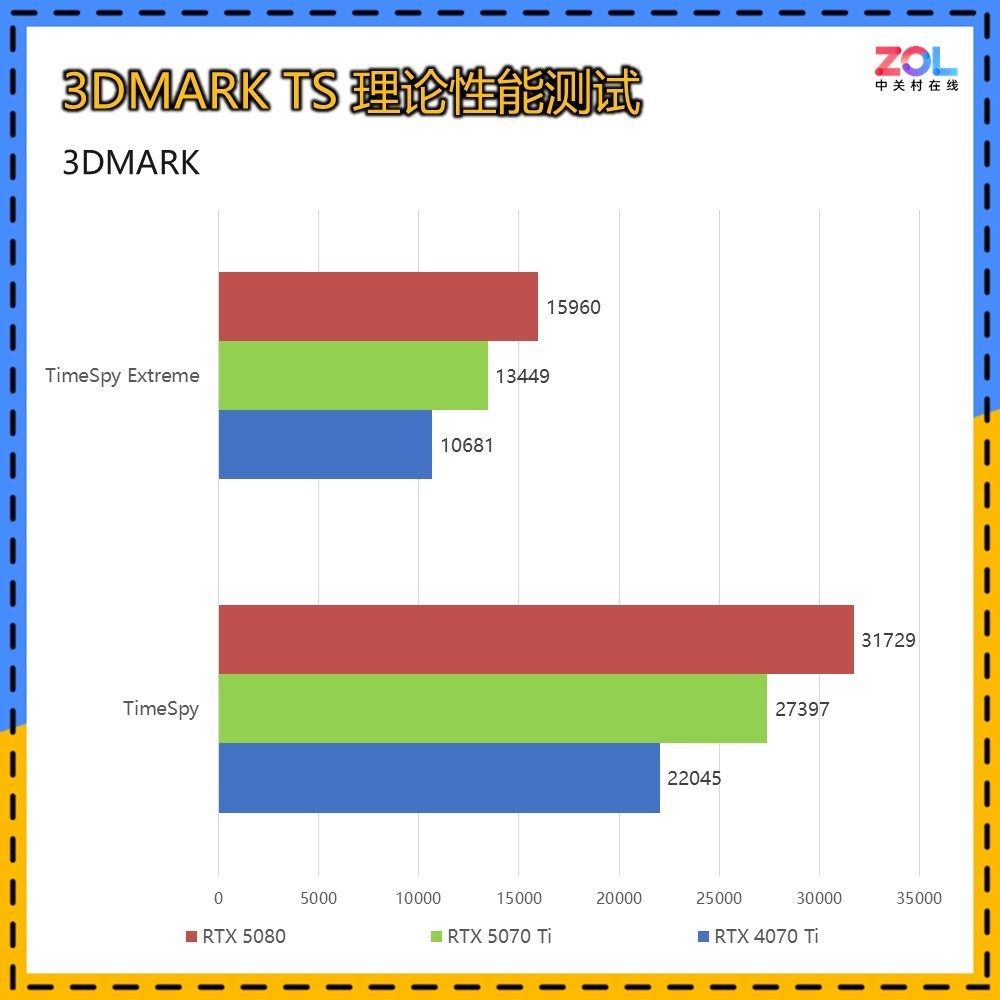
而在针对DX12环境下的TimeSpy和TimeSpy Extreme测试中,RTX 5070 Ti 16GB相较RTX 4070 Ti的提升分别为:TS提升24%;TSE提升26%,综合提升约为25%。相比RTX 5080的差距为14%/16%,综合约为15%。
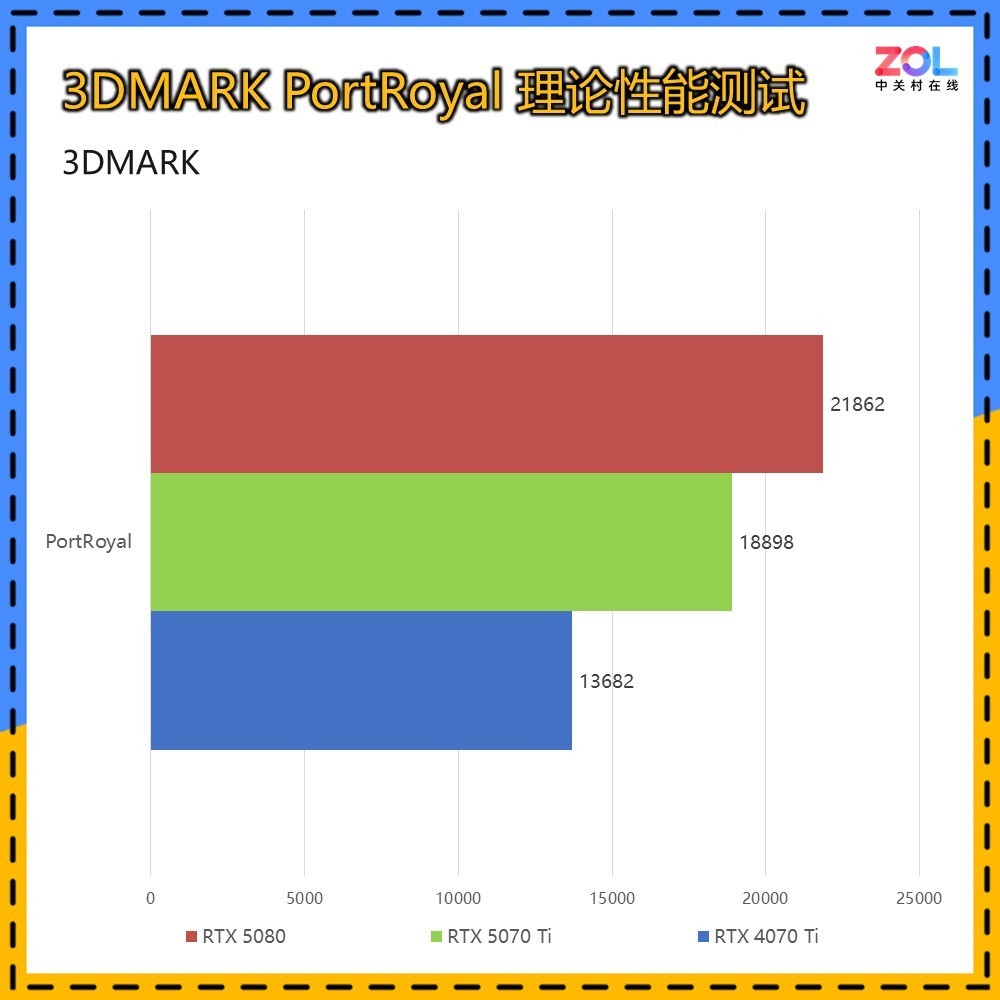
PortRoyal是3DMARK中专门针对光追性能的测试项,RTX 5070 Ti 16GB相较RTX 4070 Ti的提升约为38%;相比RTX 5080的差距为14%。
综合来看,RTX 5070 Ti 16GB的理论性能相较RTX 4070 Ti的提升约为31%。
下面我们再来看看3DMARK中新增的一些具体应用场景的测试。
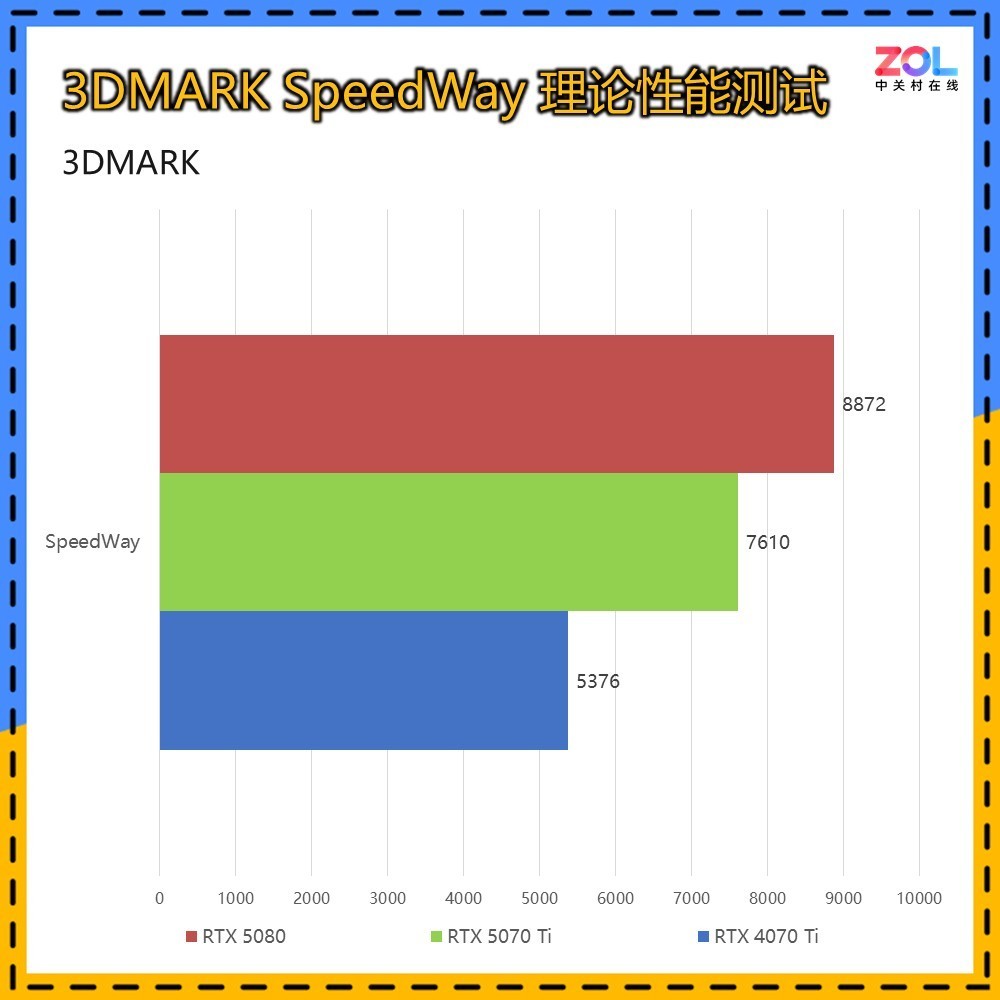
SpeedWay这项测试结合了实时光线追踪和传统渲染技术来测量显卡性能。场景含有光线追踪反射、实时全局光照、网格着色器、体积照明、粒子和后处理效果。所以SW的测试基本可以看做次世代3A游戏基准。
RTX 5070 Ti 16GB对比RTX 4070 Ti,提升为42%。从SpeedWay中不难看出,新架构在次世代3A游戏中,面对光照、粒子等后处理效果,提升会非常大。
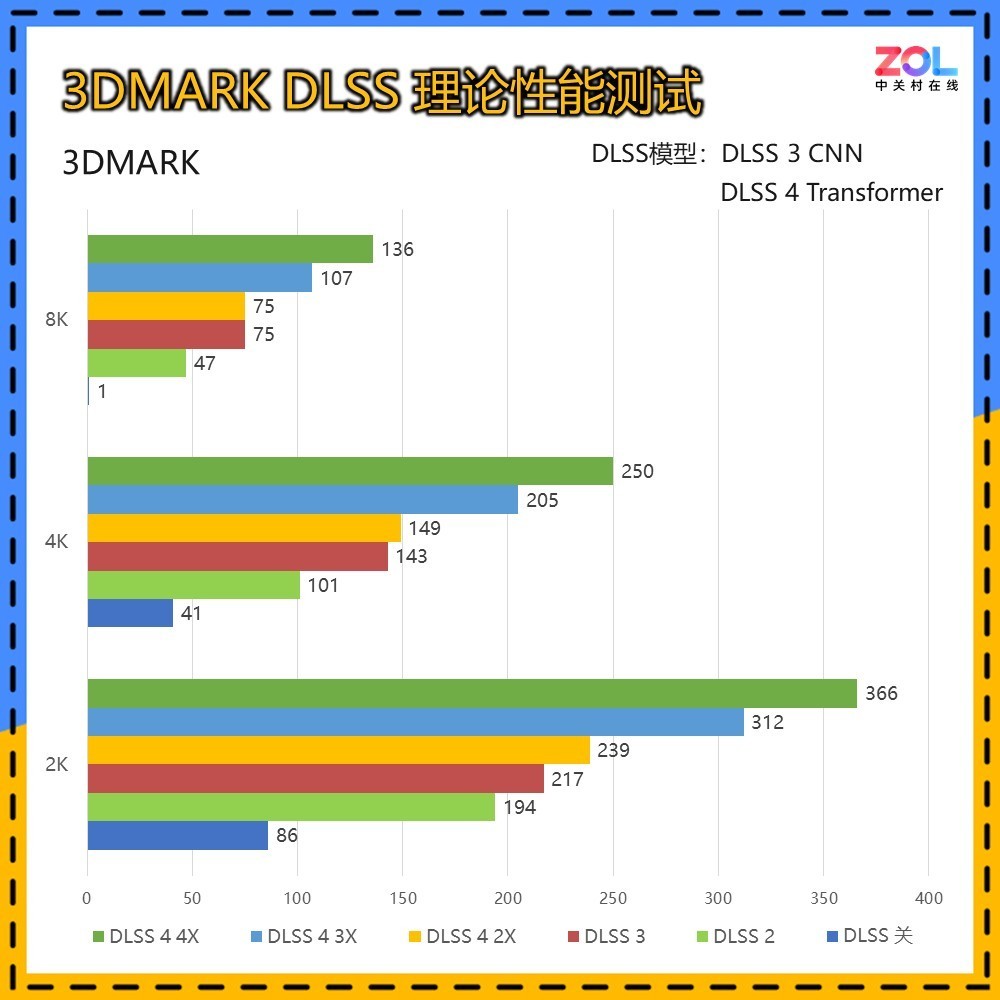
而8K分辨率,70级显卡凭借DLSS 4的多帧生成也可以达到136帧的成绩。
通过DLSS的理论测试,不难发现8K高刷对于RTX 50系显卡来说早已不是触不可及的目标,而在4K分辨率下,更是突破目前旗舰显示器的上限,达到250帧。
下面我们先实际测试DLSS 4在游戏中的表现如何,能否达到理论测试的提升效果。
本次DLSS 4在解禁首日,便可支持75款游戏或应用。除了游戏中首发支持外,对于尚未集成的游戏,可在NVIDIA app中进行直接调节非常方便。

在DLSS 4的测试中,首先来看《赛博朋克2077》,目前该游戏随着RTX 50系显卡的性能解禁,也已经更新了DLSS 4,如果首发买了显卡,也可自行测试一番。
下面的测试中我们会进行多角度对比,来看看不同DLSS的设置下,三档画质的帧数表现。
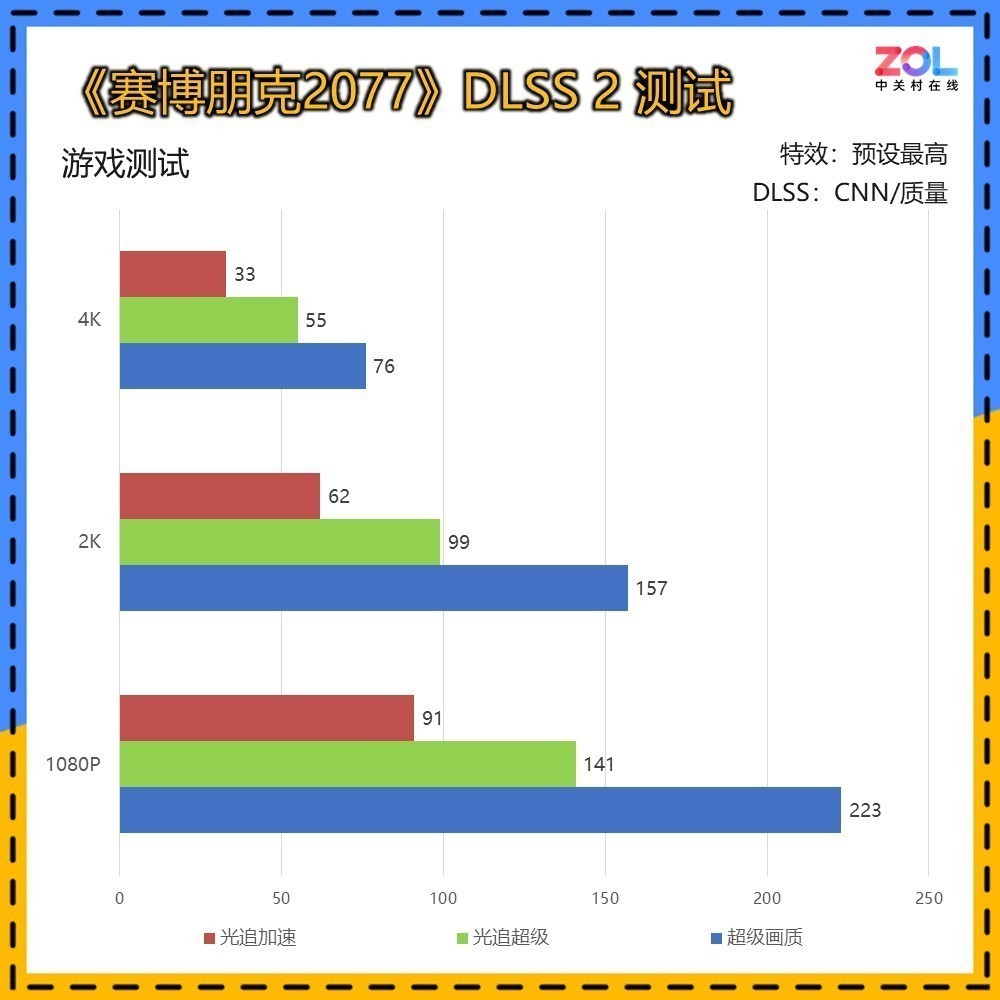
在所有测试中,为保证缩放比例固定,我们均选择在DLSS质量模式下进行。
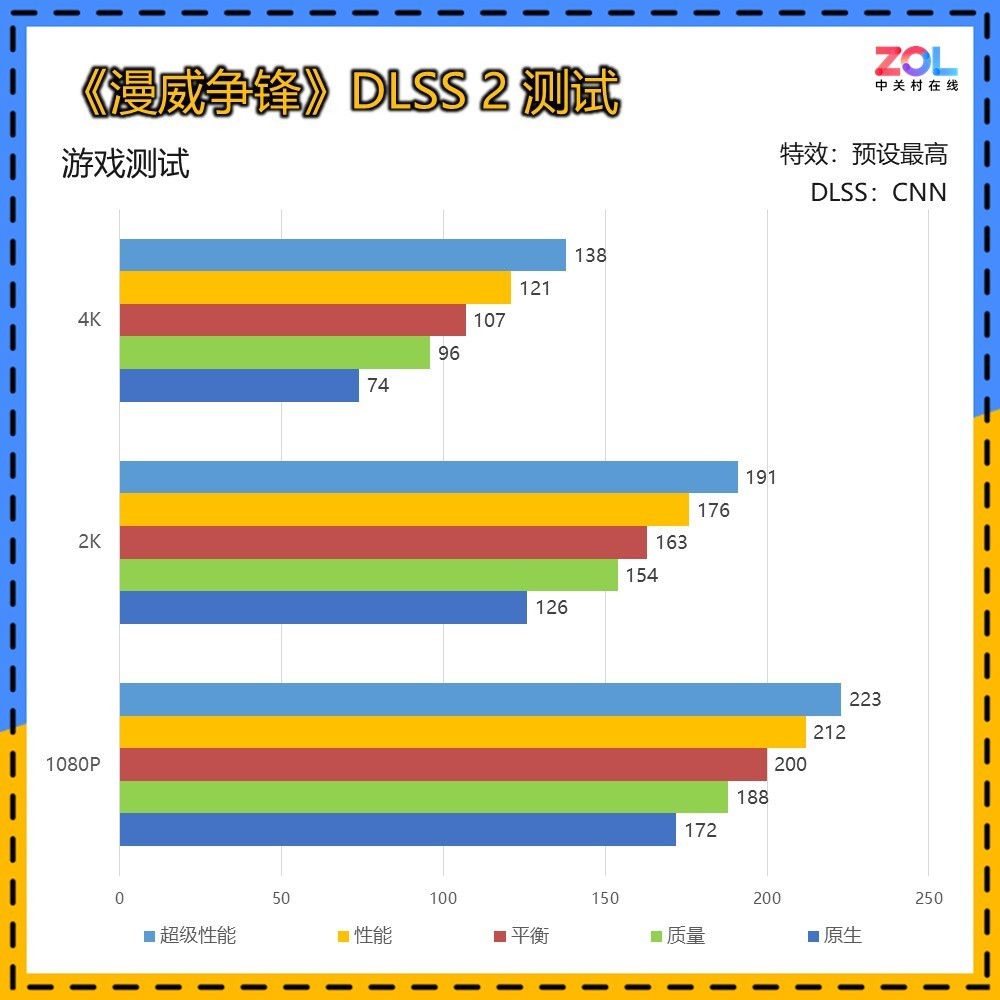
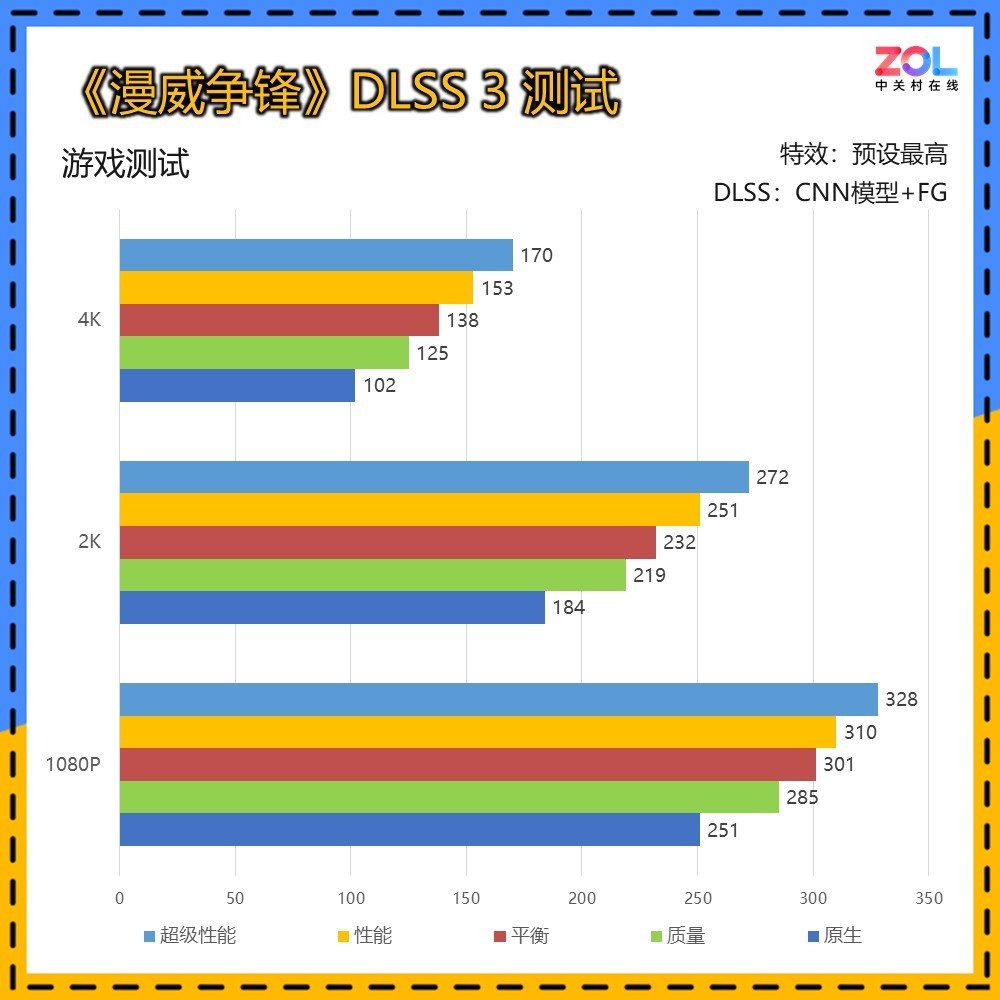
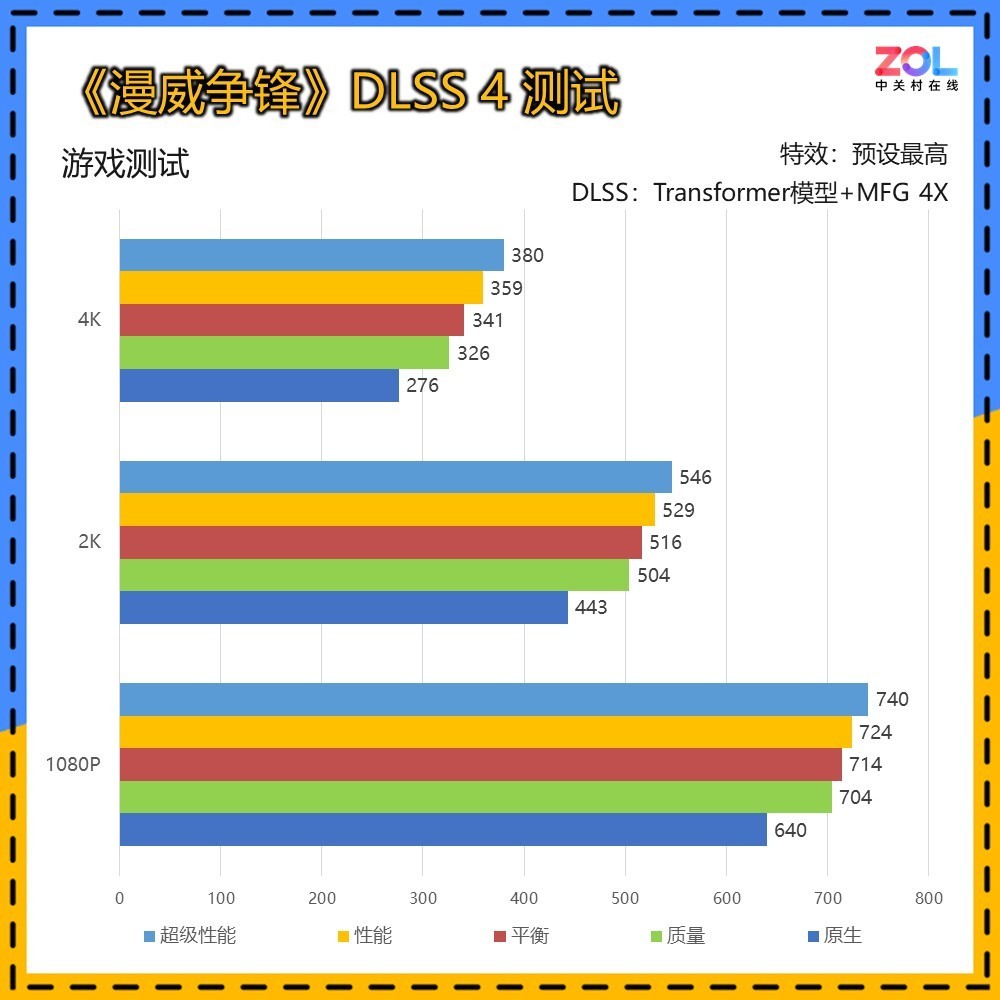
传统DLSS 2的测试中,使用CNN模型DLSS,可以看到即便是RTX 5070 Ti 16GB在4K分辨率下,光追超级画质也仅有55帧,而在光追超速模式下为33帧,尚无法达到流畅运行的成绩。
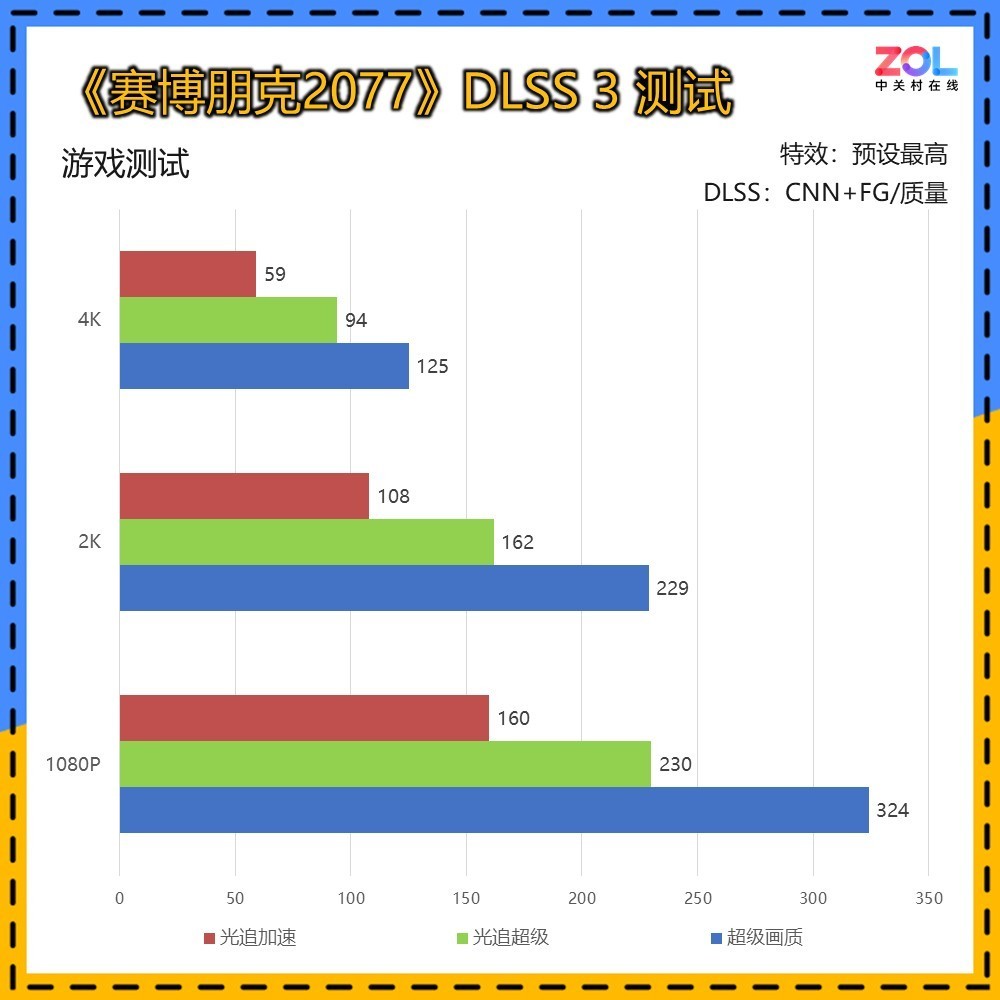
DLSS 3的测试依然为CNN模型,增加帧生成。可以看到DLSS 3已经可以大幅提升帧数,相较DLSS 2,在4K超级画质/光追超级/光追加速的提升分别为64%/71%/79%,综合提升71%。
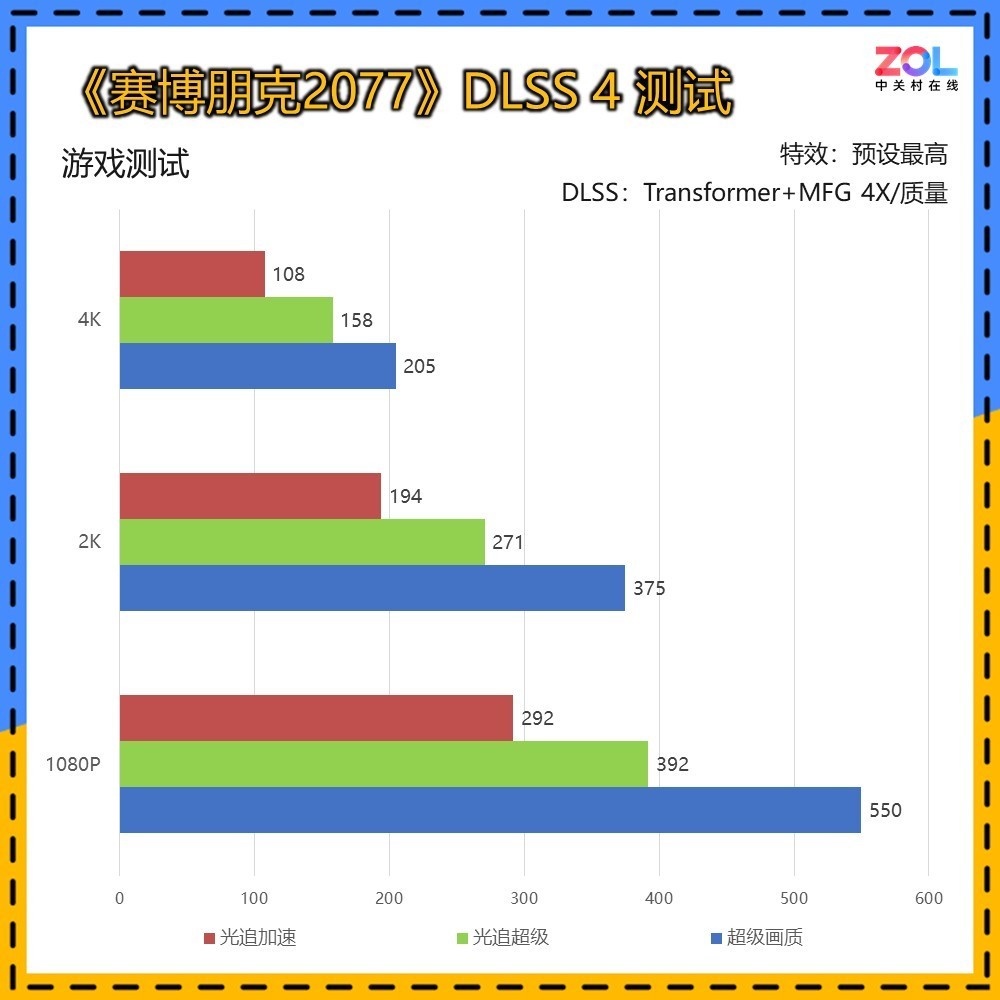
DLSS 4的测试为Transformer模型4X帧生成模式,在4K超级画质/光追超级/光追加速中,相较DLSS 3的帧生成提升分别为64%/68%/83%。
除了帧数上的提升,DLSS4对于画质表现如何,下面我们来看看实机截图对比。

可以看到在采用Transformer模型的DLSS4中,物体表面的纹理细节更清晰。即便是没有模型面覆盖的锈迹,DLSS 4依然能精准还原。

同理,墙上的裂纹在DLSS 4中有更明显的痕迹。并且整体画面相较于DLSS 3,更通透明亮。大家也可4K图片自行比对。
《漫威争锋》是近期大火的FPS+MOBA类网游,最初被看作《守望先锋》的替代品,但实际游玩效果,无论画面还是玩法,都更胜一筹。
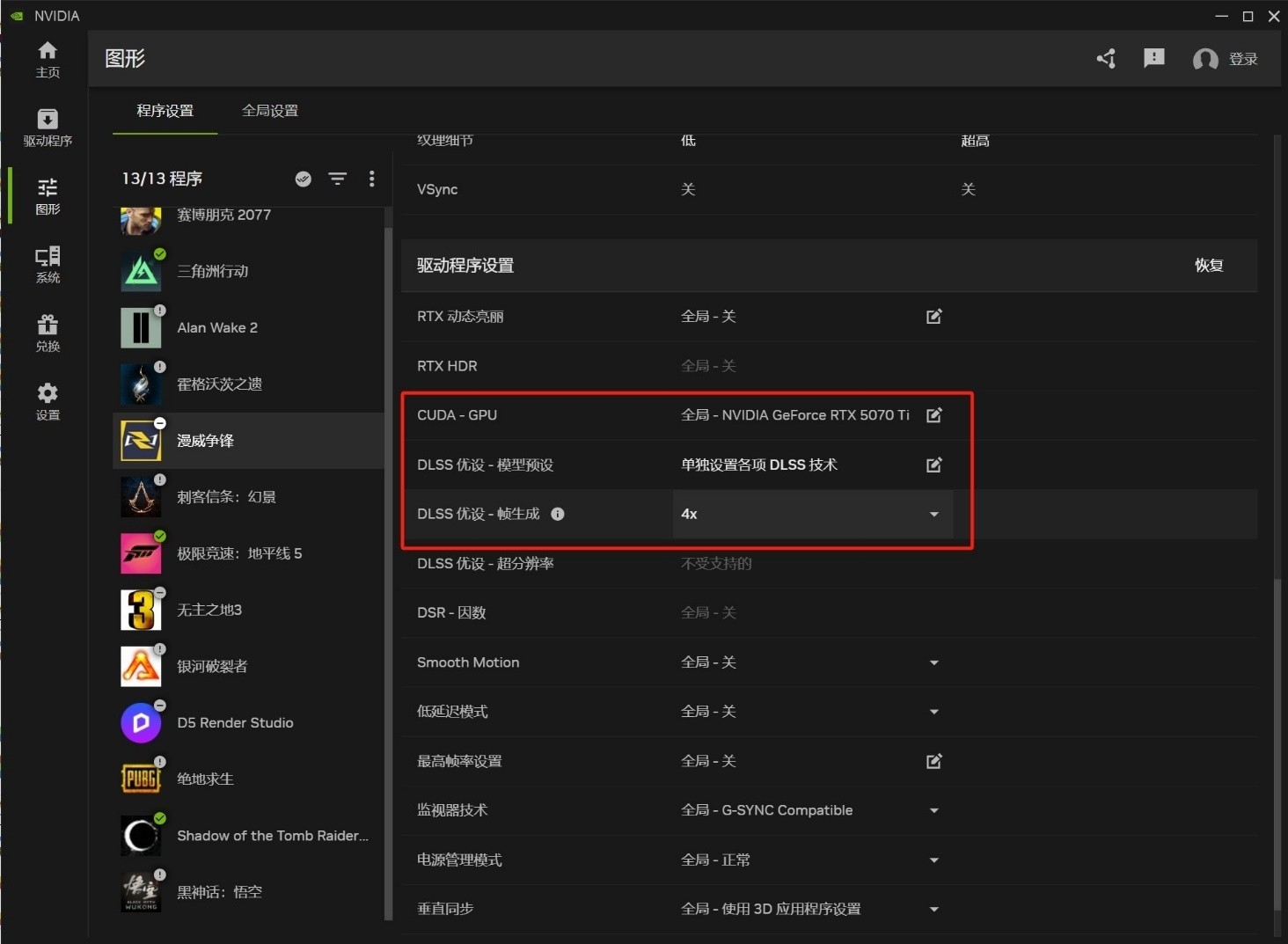
目前《漫威争锋》尚未在游戏中集成DLSS 4,这里也举例说明在NVIDIA app中如何开启DLSS 4。
打开NVIDIA app后,切换至图形选项卡,找到对应的游戏,拉至最下方【驱动程序设置】,找到DLSS模型预设,将内部选项全部调节至最新后,开启DLSS帧生成4X,即可享受帧数的暴力加成。
注意在调节后需重启游戏,且游戏中的DLSS设置及名称不会发生变化,仍然可调节质量、平衡、性能等挡位,但对应的则是DLSS 4X。
对于一款竞技网游来说,高帧率比画面更重要,使用RTX 5070 Ti 16GB在4K分辨率下,DLSS 2质量模式已经能够达到百帧。
在DLSS 4 4X多帧生成中,4K分辨率相比DLSS 3质量模式再提升161%,达到326帧。至于大部分超高刷的1080p FPS电竞显示器,原生640帧也已经完全能够顶格跑满了。
这里值得一提的是,或许是游戏优化或驱动更新的原因,此次DLSS 4 4X测试相比RTX 5080时测试帧数更高。
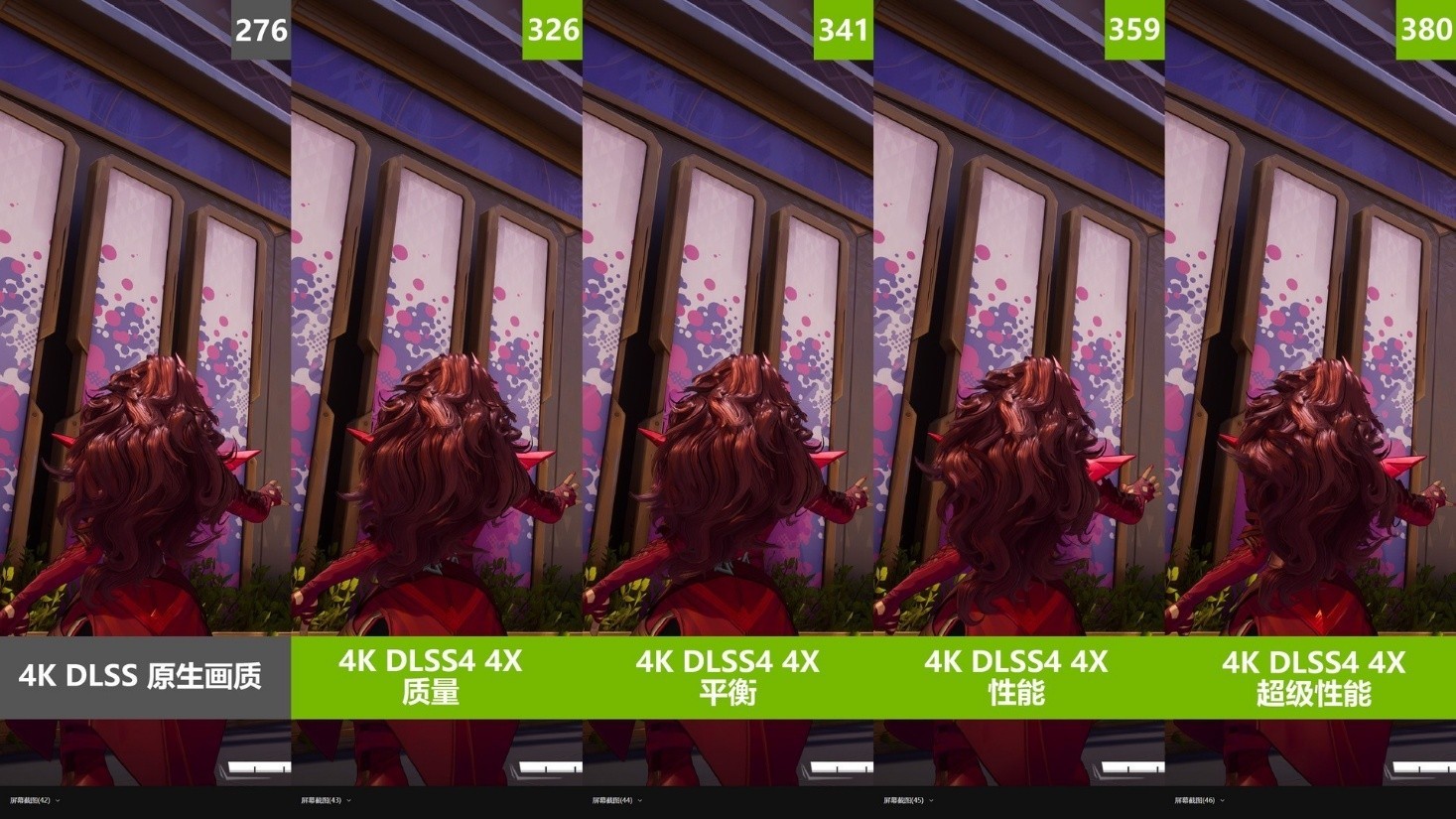
在画面对比中,DLSS 4 4X的四档画质也很难看出区别,角色的头发、衣服,远处的建筑涂绘,基本都和原生画质分毫不差。
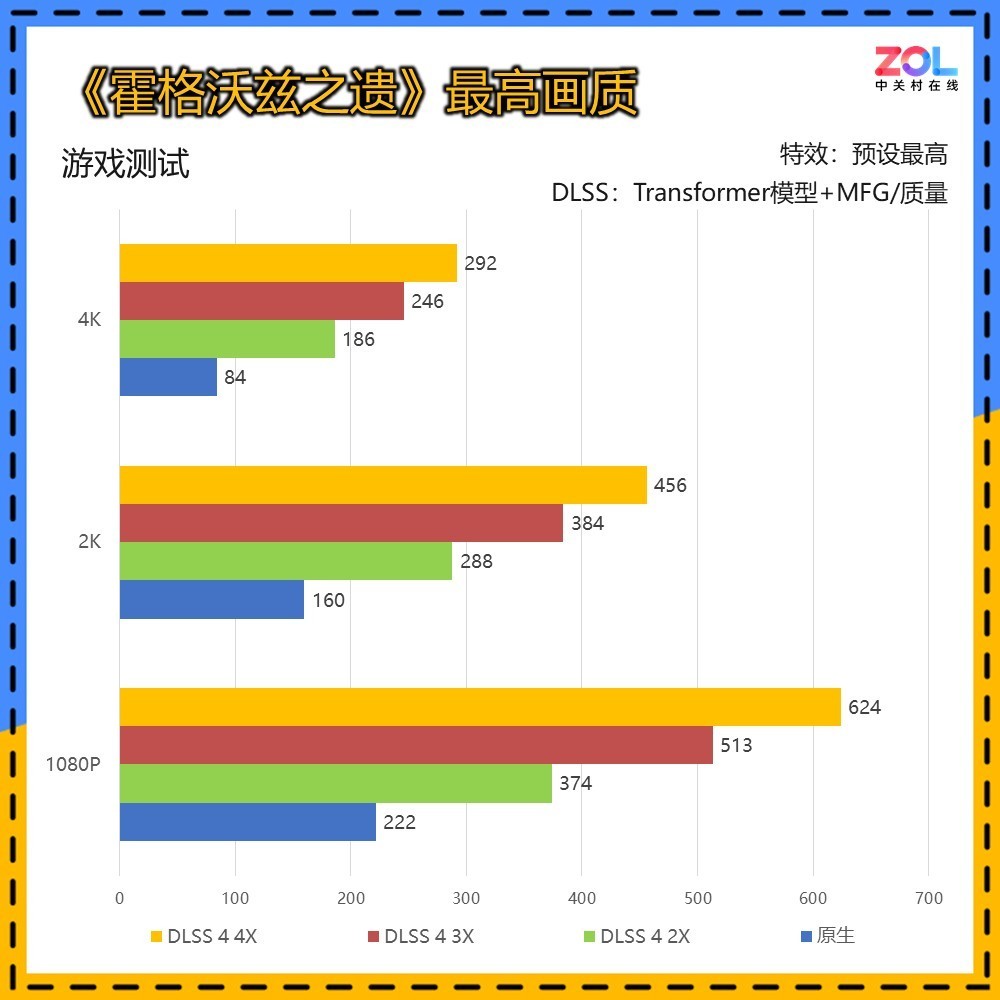
本次新增了《霍格沃兹之遗》的帧数测试,该游戏所有DLSS相关测试均在“质量”模式下进行。首先来看无光追最高画质,4K分辨率下RTX 5070 Ti 16GB在DLSS 4 4X下可达到292帧的成绩。
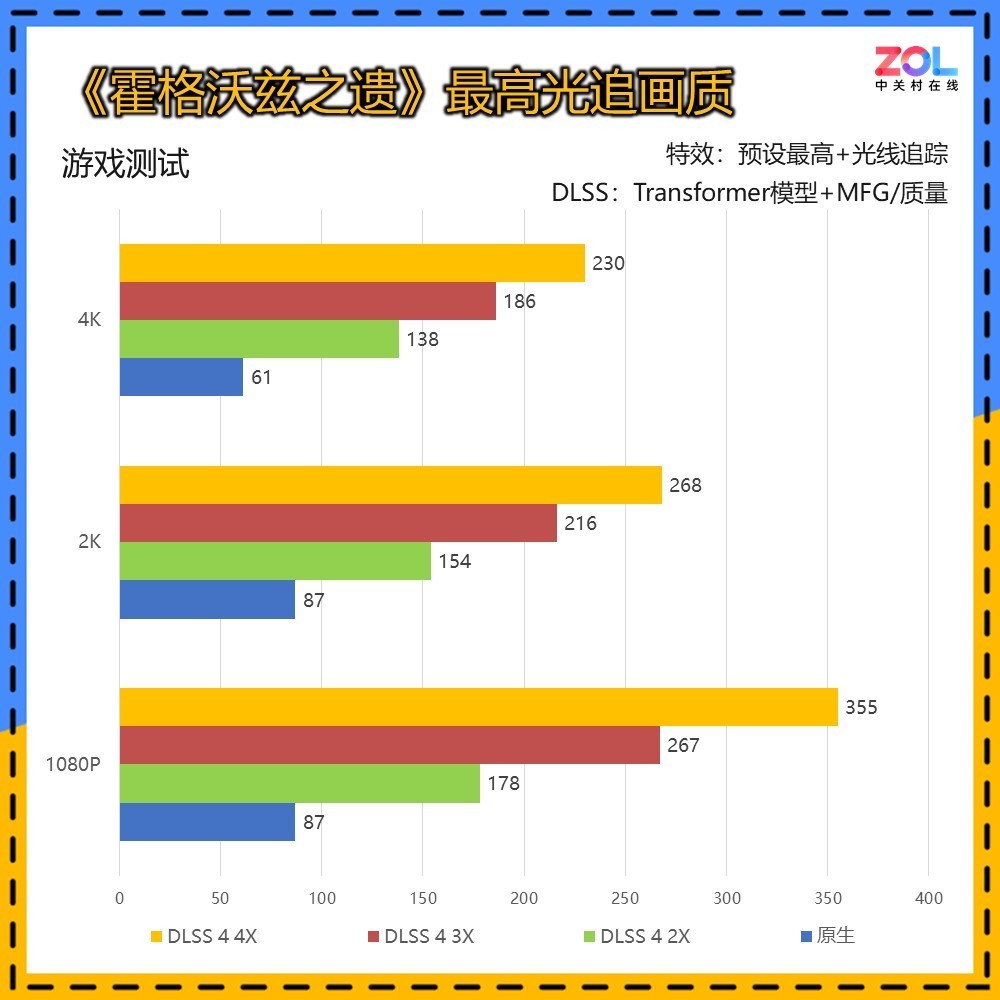
而在开启光线追踪后,《霍格沃兹之遗》对性能要求激增,不过有DLSS 4的加持,4K分辨率的最高帧数依然能达到230帧。

打开光追后,虽然对于配置要求激增,但同样画面表现有着明显区别,其中最明显的则是水体,能够明显看出随着深度不同,水体颜色的变化。

另外光线重建则能够修复一些画面的细节表现,比如图中圈出的部位,开启光线重建后,建筑的光影层次更分明。
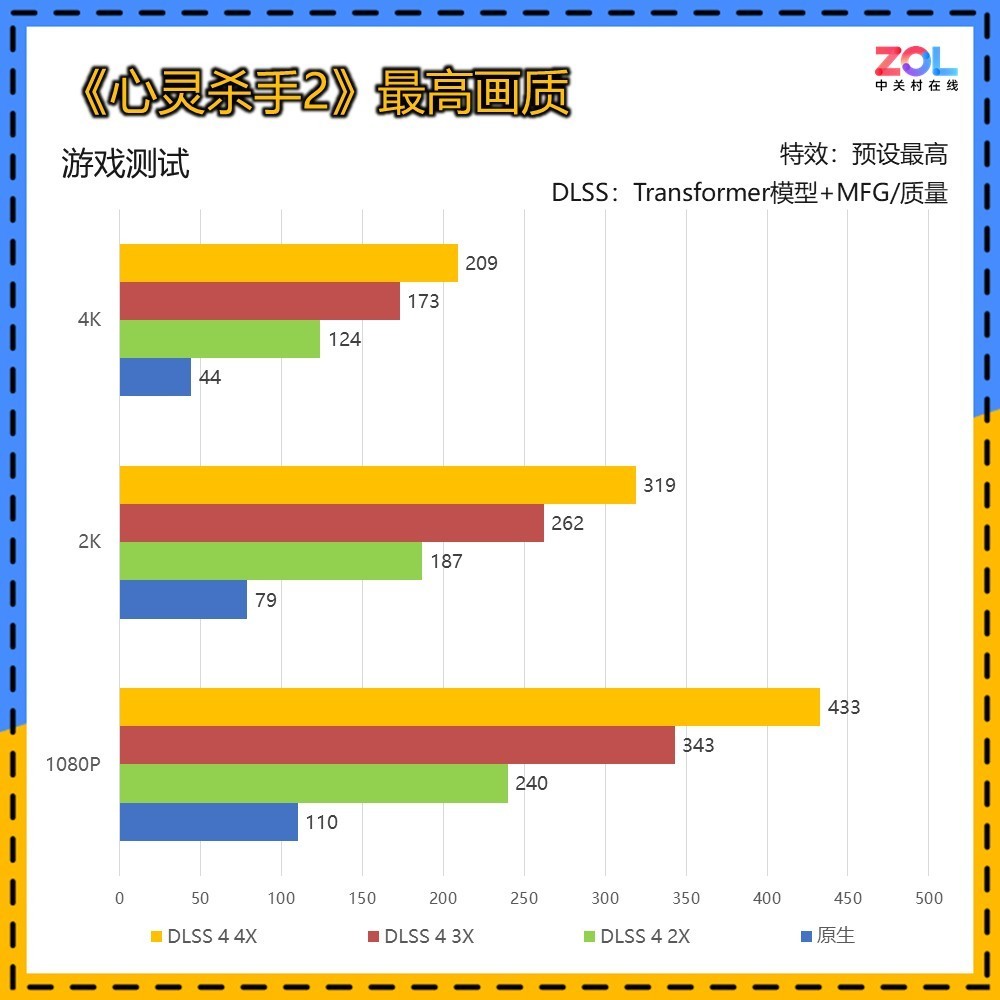
《心灵杀手2》是被誉为次世代最强画面的游戏,对于配置需求极高,但同时画面表现堪称完美。不过在不开启光追,默认最高画质下,对配置的要求还比较亲和,RTX 5070 Ti 16GB在DLSS 4 4X的加持下,可以达到209帧的成绩。
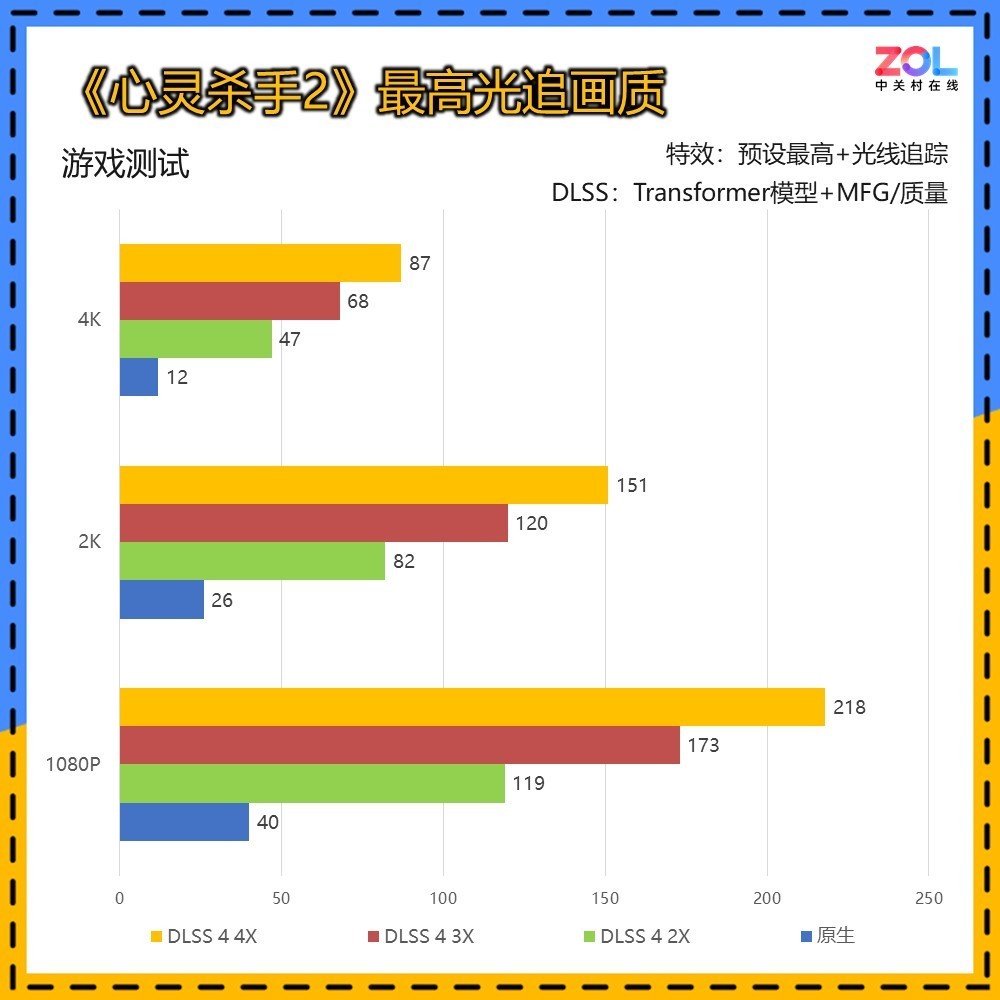
而开启光追后,虽然仍有多帧生成的加持,但4K分辨率最高也仅有87帧。下面来看看开启光追后的画面有何区别。


《心灵杀手2》整体画面较为昏暗,但光影氛围刻画非常到位。在开启光追后,阴影的表现更清晰,更符合真实的物理表现,同时水体与《霍格沃兹之遗》相同,均能够表现出水潭的深浅,相比原生画质,游戏的代入感更强。
6《鸣潮》光线追踪画质对比
二游是目前非常火热的游戏领域,早期二游画面以卡通风格为主,不过近几年也开始“卷起来”了。《鸣潮》近期即将引入DLSS帧生成以及光线追踪,让画面和帧数都有更好的表现。下面我们来看看实机演示效果。
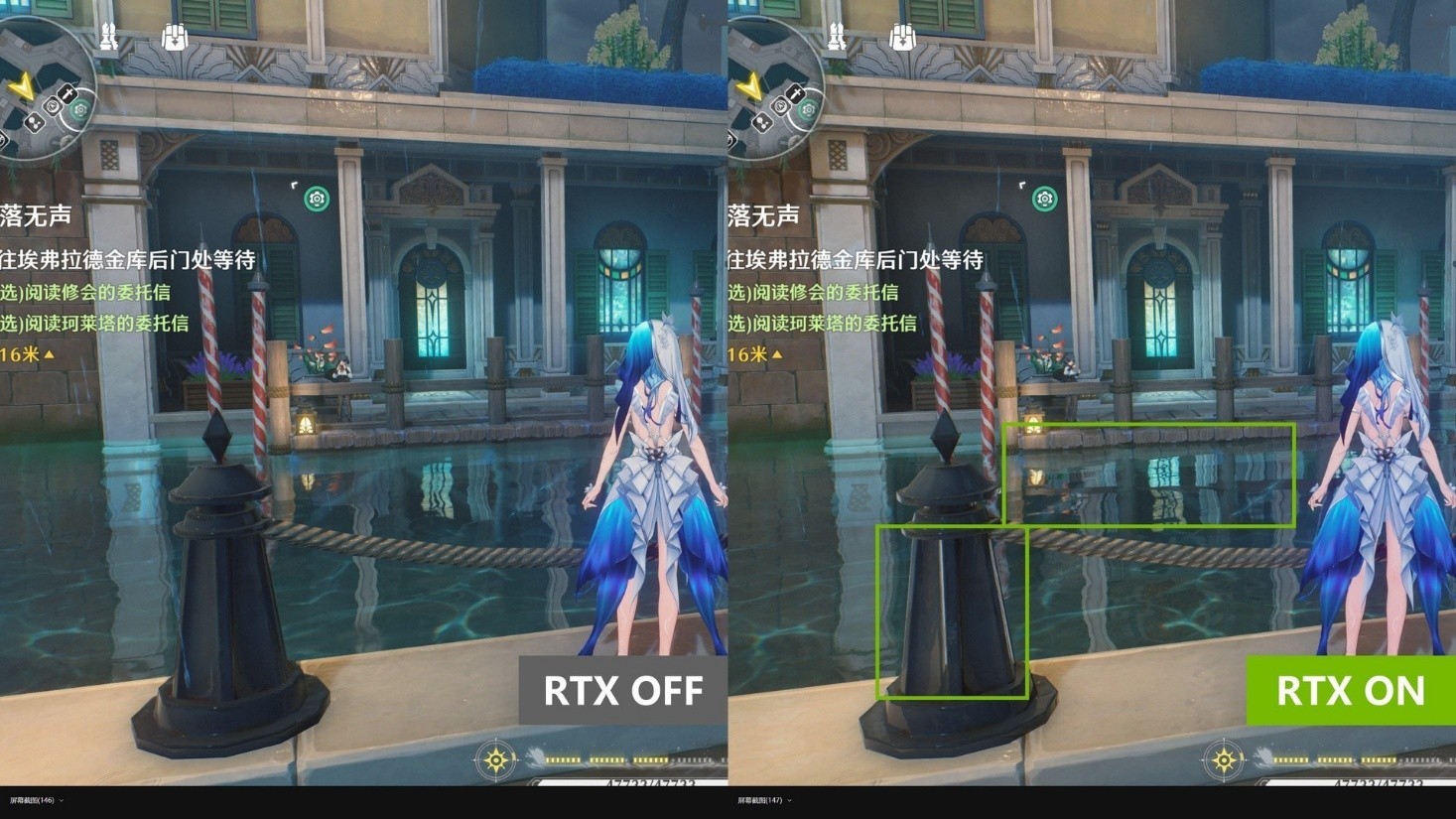
光追较为明显的区域永远离不开水面,从图中可以看到开启光追后,对面NPC在水中的倒影更清晰,且水面线与建筑的过渡更柔和。而近处物体也能够吸收地面二次反射的光线,让轮廓更清晰。

在玻璃上的光追反射就不用说了,甚至光追的加入,能够让玩家解决永远看不到绝对领域的“BUG”。
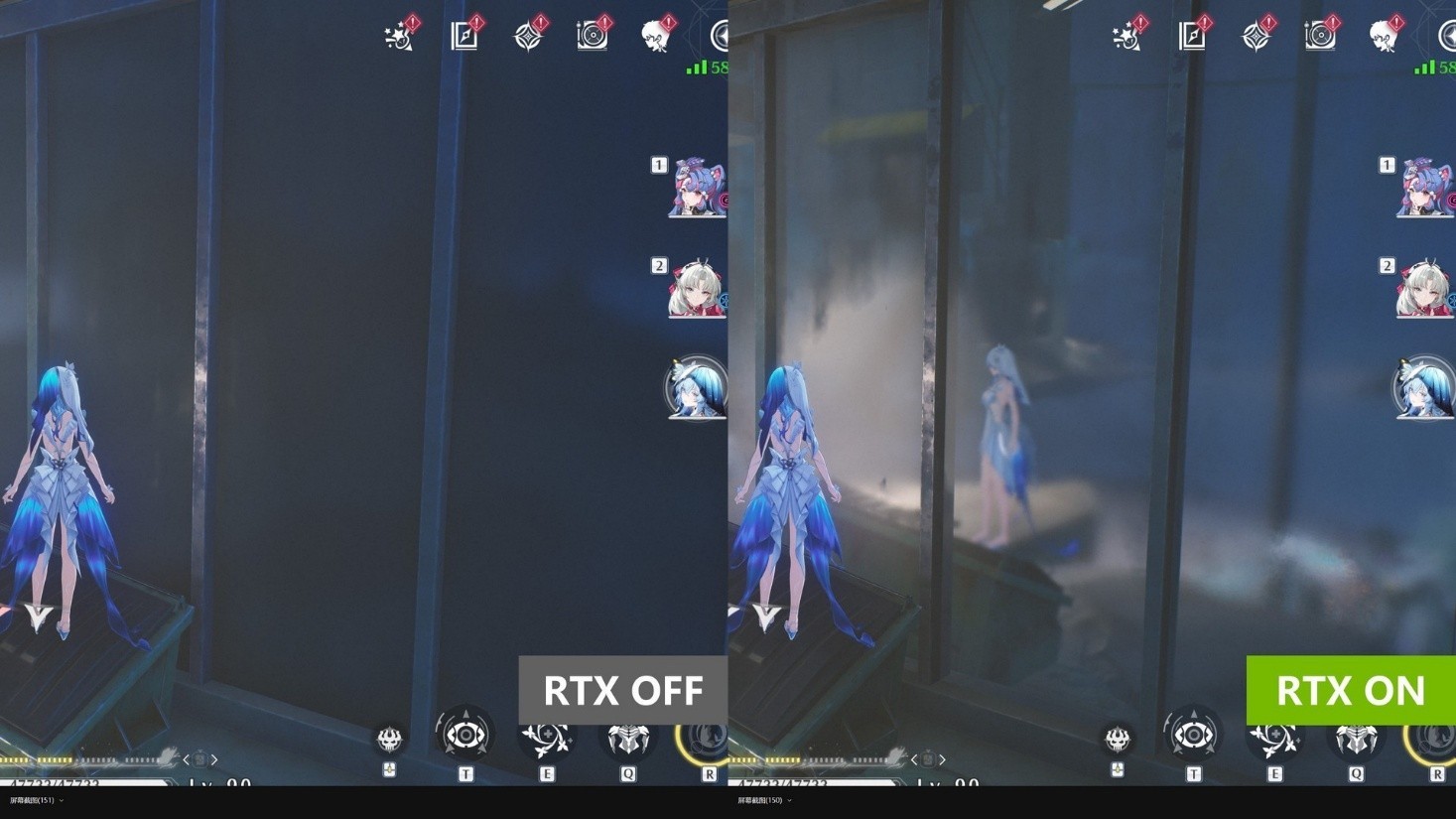
另外在玻璃的反射中,除了主角能够清晰映射,注意右下角的小怪也能一同出现在玻璃中。
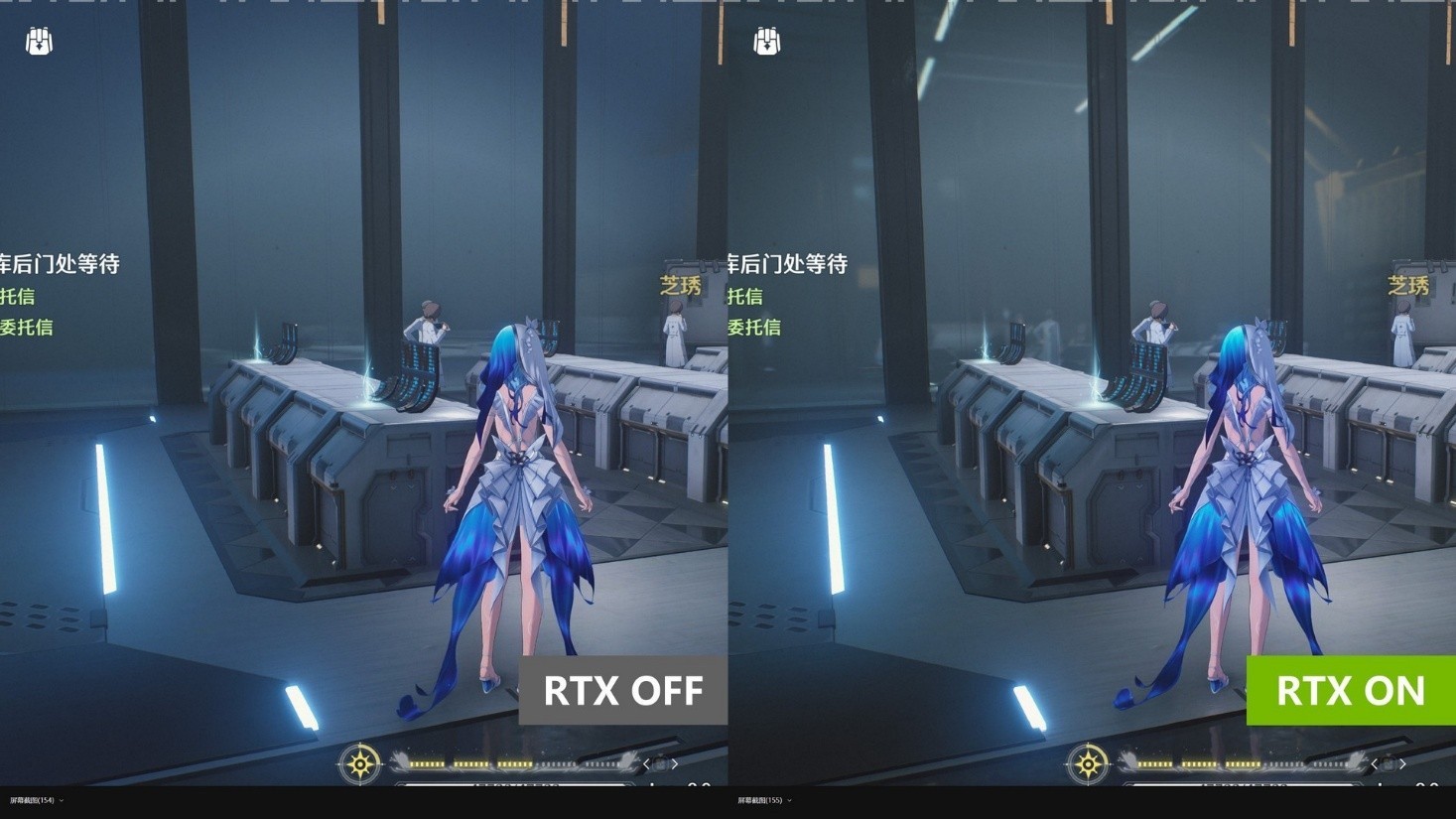
玻璃的反射除了方便观察绝对领域,还能够为室内场景增加沉浸感,开启光追后,对面玻璃能够反射出屋顶的灯光,让整个室内更立体。

绝对领域绝对领域,相信光追的加入,能够让不少玩家更兴奋了~
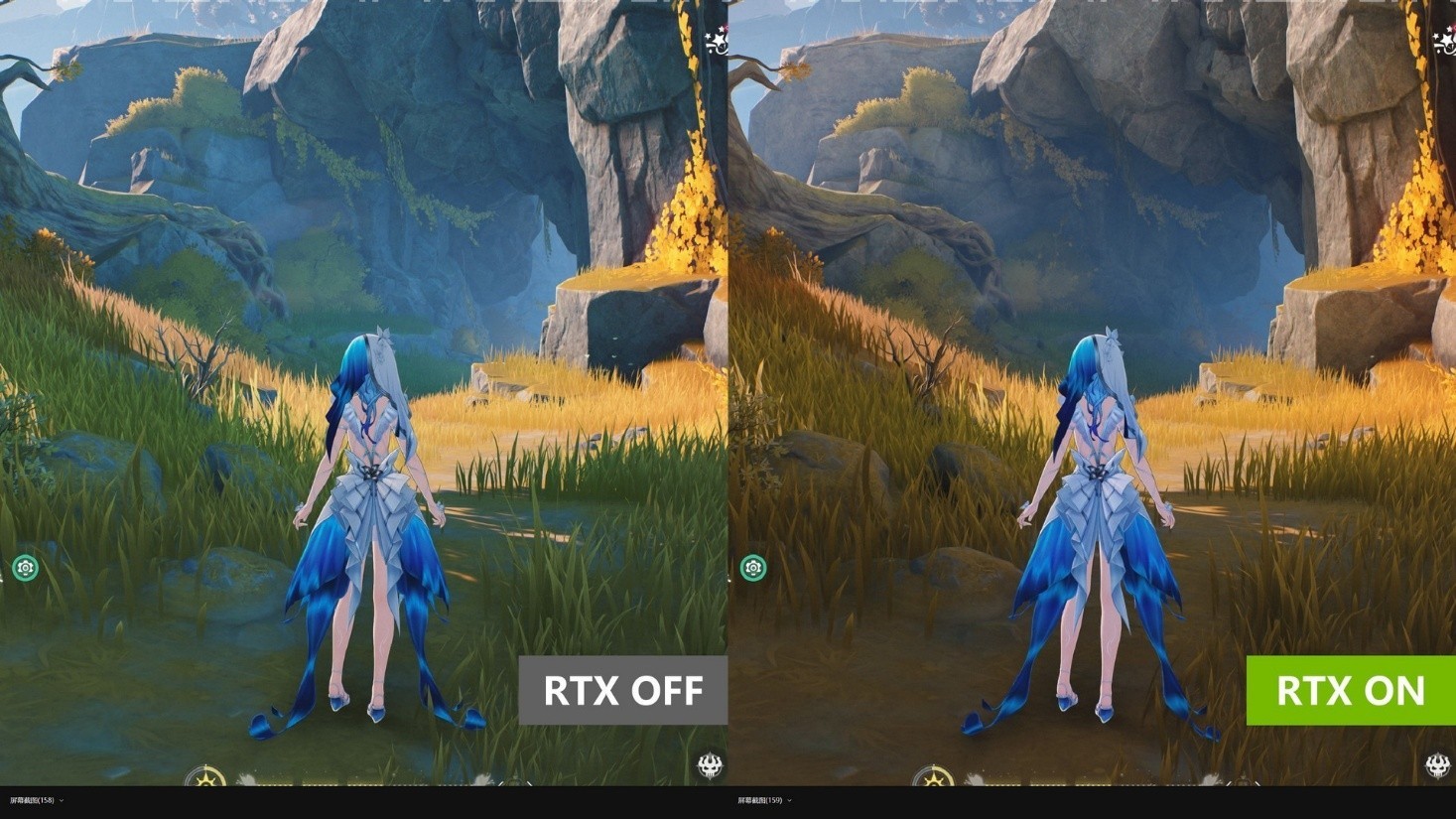
另外一个比较重大的变化,则是在室外光照较为强烈的场景。如云岭谷,在开启光追后,全局光照能够结合场景的光照条件,将光线的反射映射到整个峡谷中,甚至整体色调都发生了变化,沉浸感相当强。
7常规游戏性能测试
除了支持DLSS 4的游戏,我们同样测试了一些主流的3A大作和支持DLSS 3的游戏,为更多玩家提供参考方向。
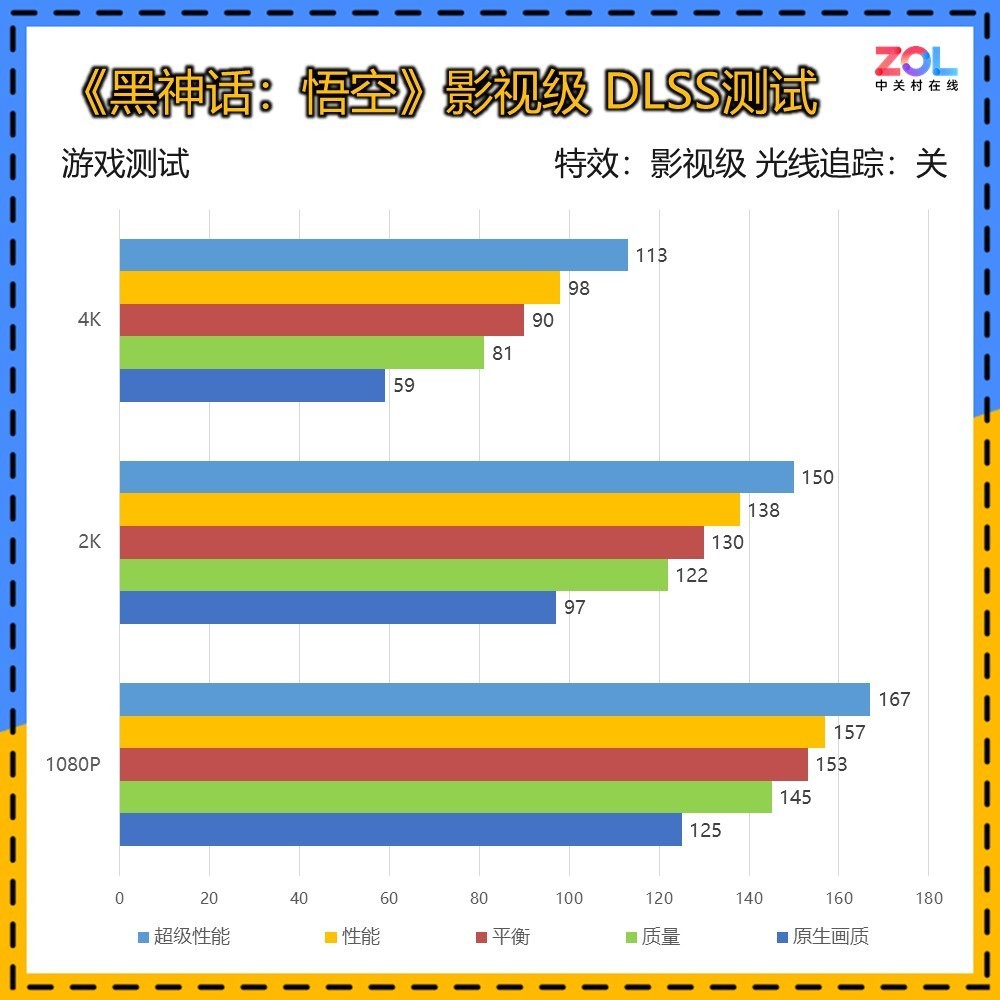
《黑神话:悟空》是一款妇孺皆知的国产虚幻5巨制,自带DLSS 3帧生成。我们的两项测试也全部开启帧生成,均为影视级画质。实测RTX 5070 Ti 16GB在4K分辨率下最高已经达到了113帧。
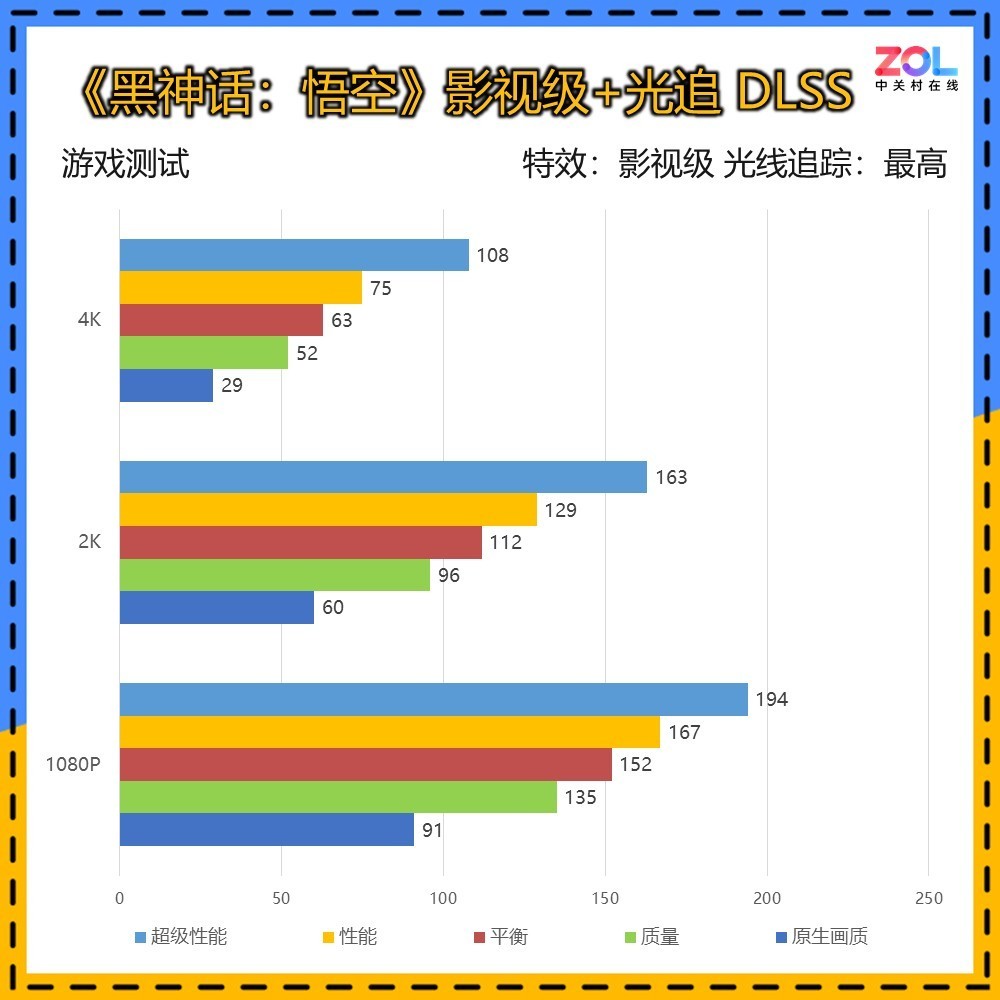
在开启光追后,《黑神话:悟空》对于配置的要求还是相当高的,不过从我们此前的测试来看,使用虚幻5引擎的《黑神话:悟空》不同DLSS档位下的画质几乎没有差距。
如果扔想获得比较高的画质,4K分辨率下可以选择性能模式游玩,对于很多风景党来说,可既享受高帧率的同时,又不损失画质。
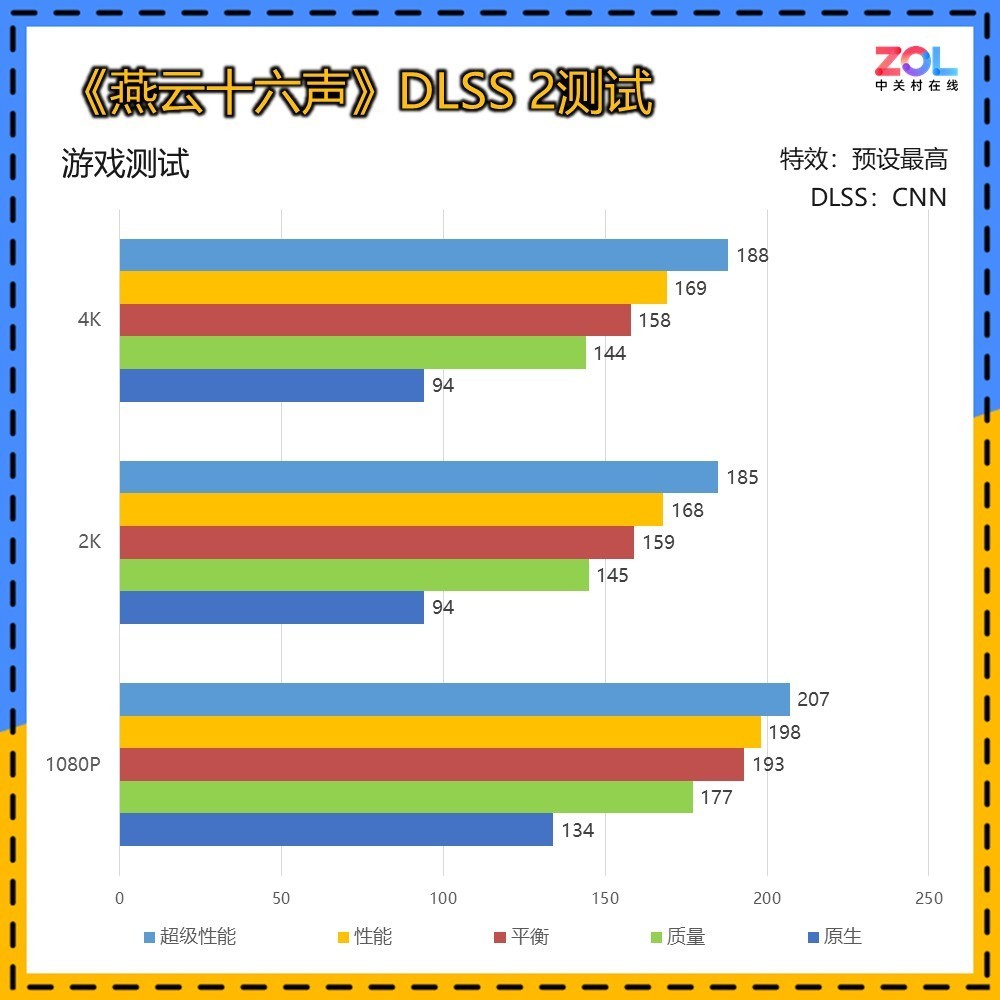
《燕云十六声》是网易开发的一款国产武侠大作,在DLSS 2的测试中,2K与4K的成绩几乎完全相同。这绝对是目前游戏优化尚不完善,至少在低分辨率下RTX 5070 Ti 16GB的表现应该更好。
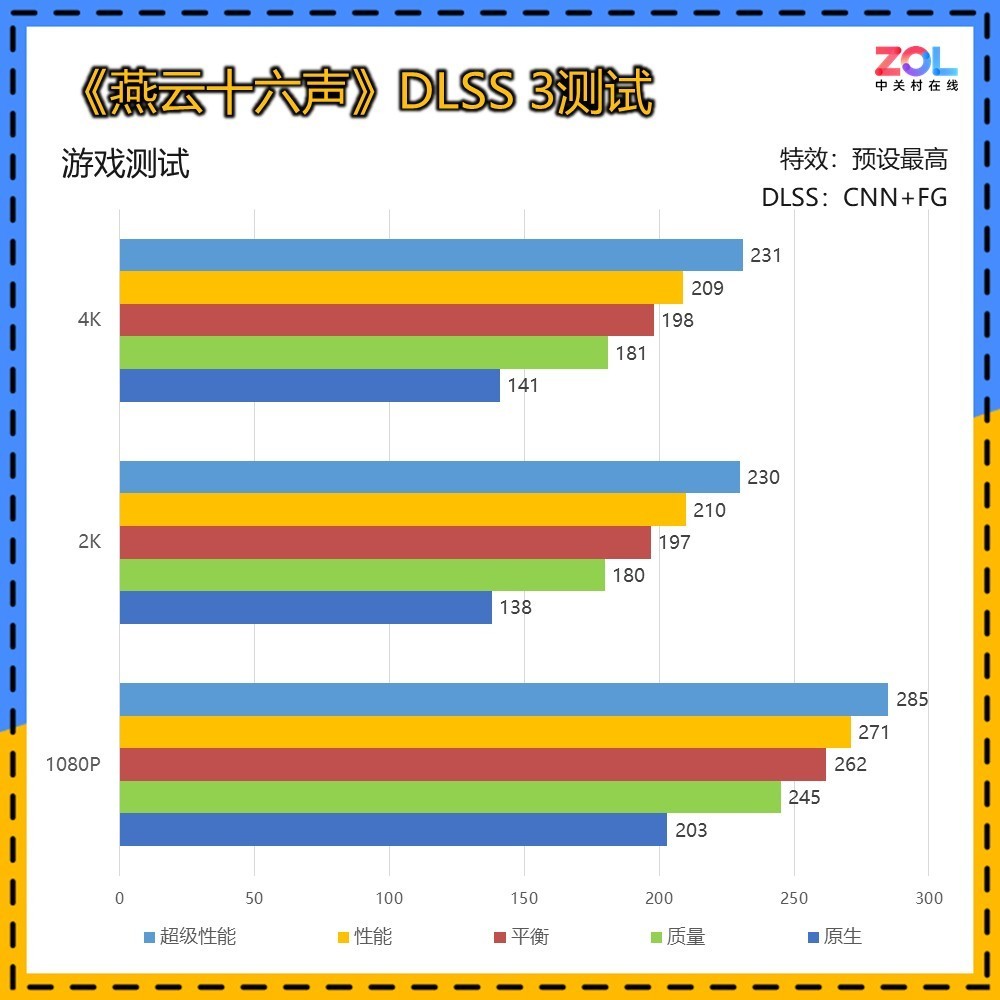
而在DLSS 3的测试中,仍然出现了DLSS 2中的问题。不过在4K分辨率下RTX 5070 Ti 16GB大部分DLSS成绩均在200帧左右徘徊。
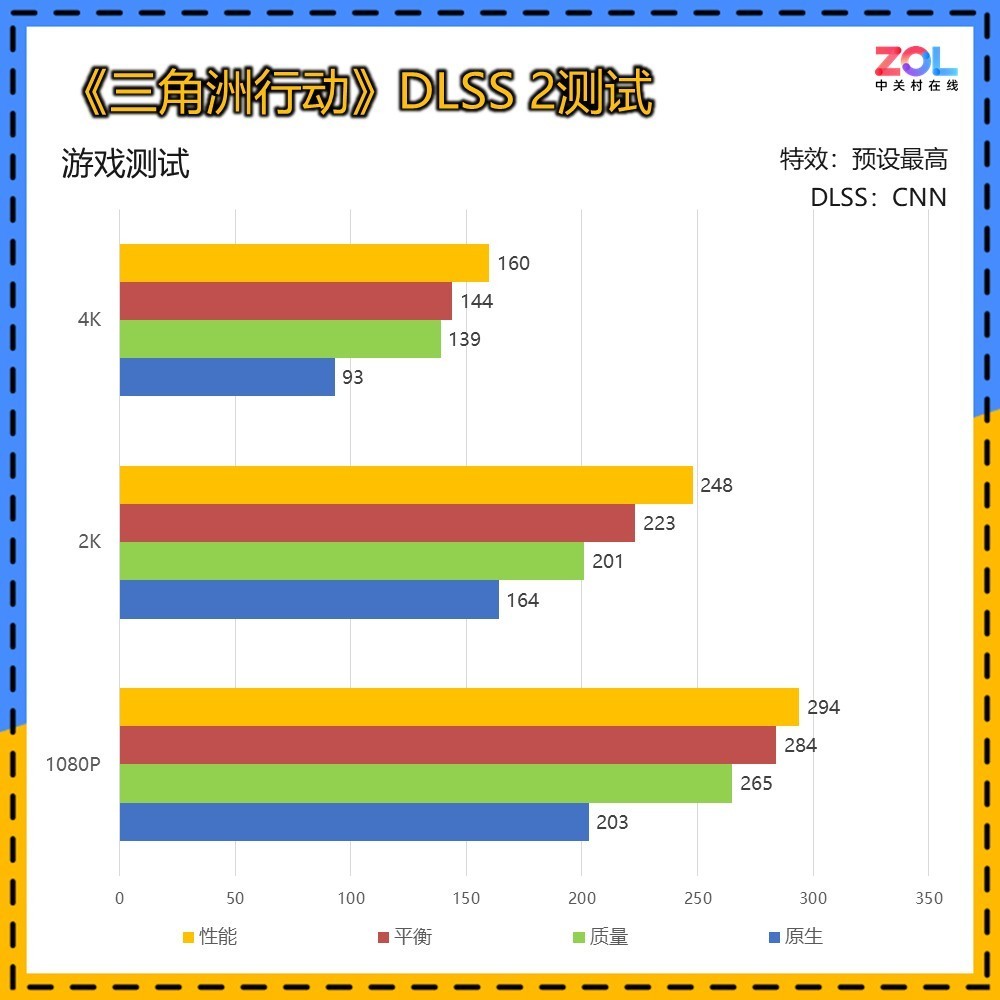
近来同样大火的《行动》测试中,RTX 5070 Ti 16GB在4K分辨率下,DLSS 2的结果已经达到了140帧左右的电竞级体验。不过FPS网游会受到多种因素影响帧数,如周围玩家、环境复杂程度、网络等等,所以测试结果仅供参考。
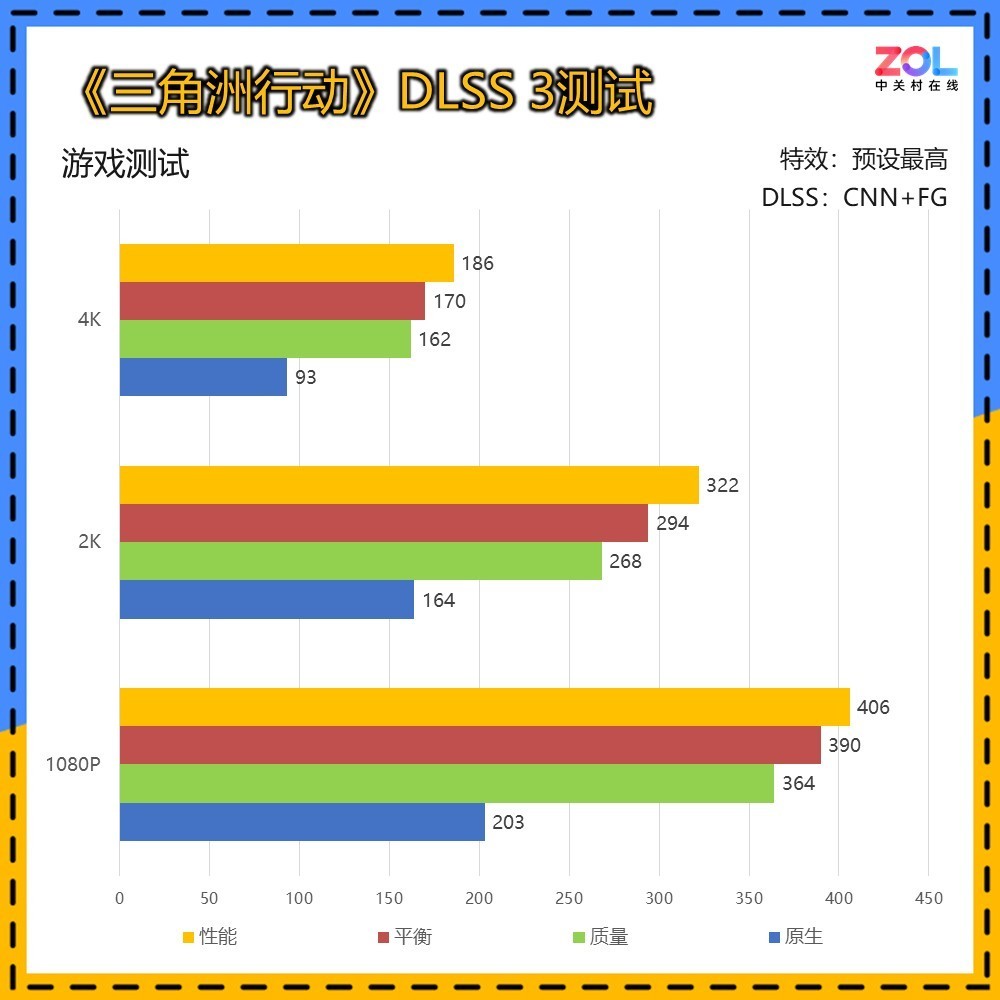
而在加入帧生成的测试后,帧数进一步拉开。但RTX 5070 Ti 16GB在4K分辨率下的成绩,相较DLSS 2提升不如低分辨率下明显。
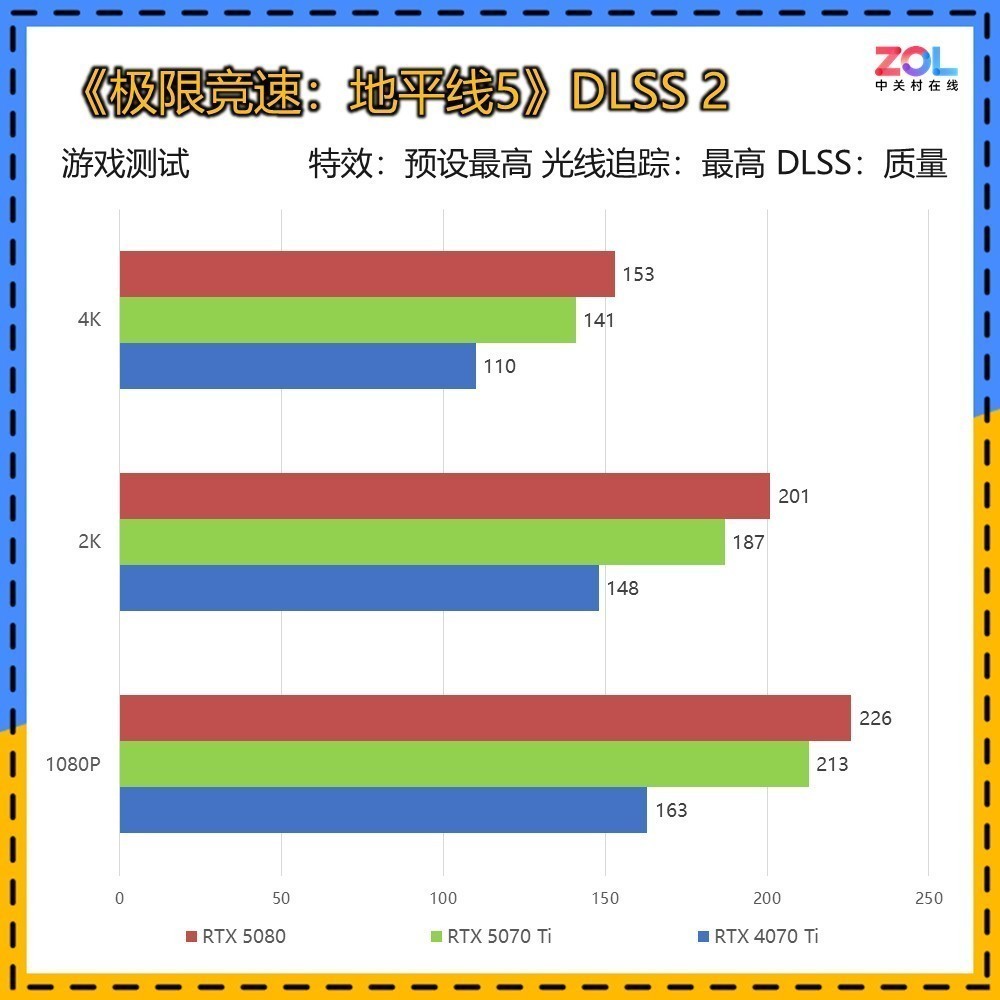
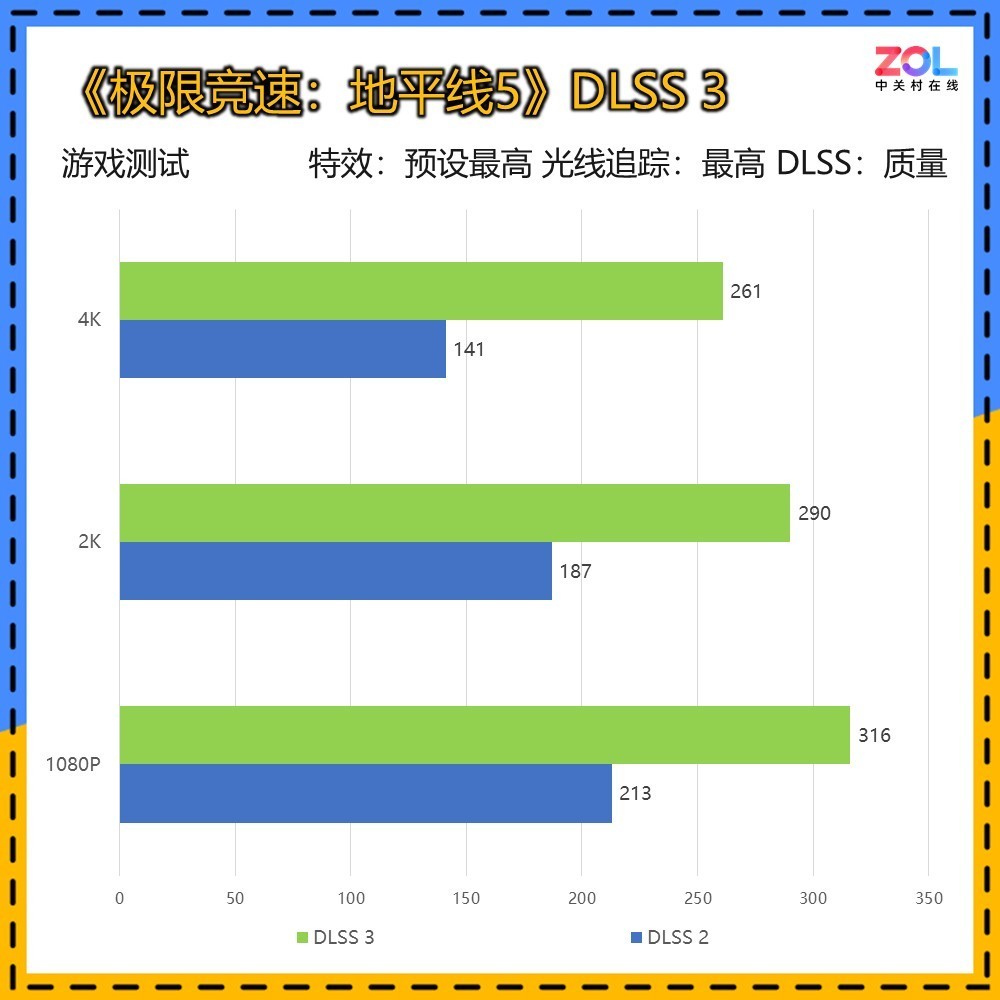
《地平线5》也是显卡测试的常驻游戏,其凭借出色的优化,在原生效果下即可跑出优秀的成绩。RTX 5070 Ti 16GB在DLSS 3 4K分辨率下再创新高,提升将近一倍的成绩。这在此前RTX 5080的测试中也不曾达到,看来随着驱动不断优化迭代,对游戏的支持度也更加完善。
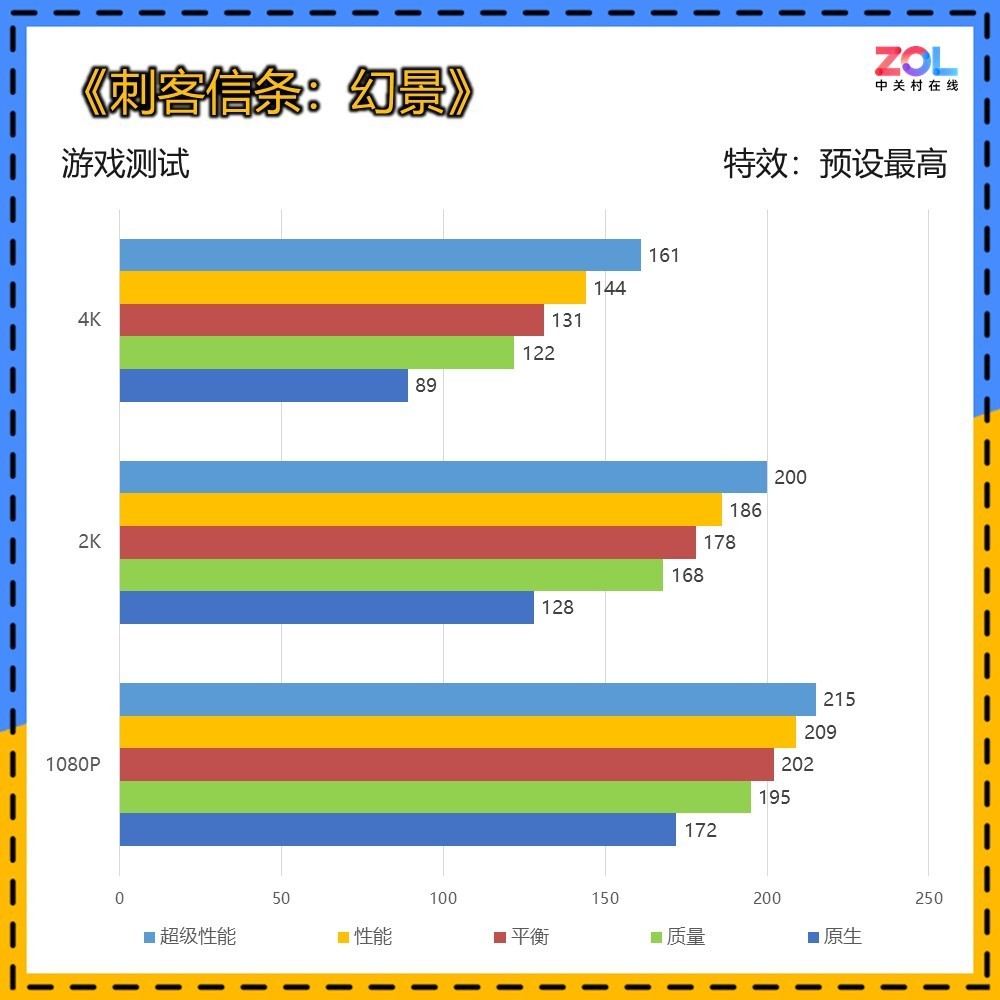
在《:幻景》中,我们关闭游戏的自适应帧率,分别测试DLSS不同挡位与原生画质下的差异。
RTX 5070 Ti 16GB在4K分辨率原生画质下为89帧,而在DLSS质量挡位中,便达到122帧的出色水平。
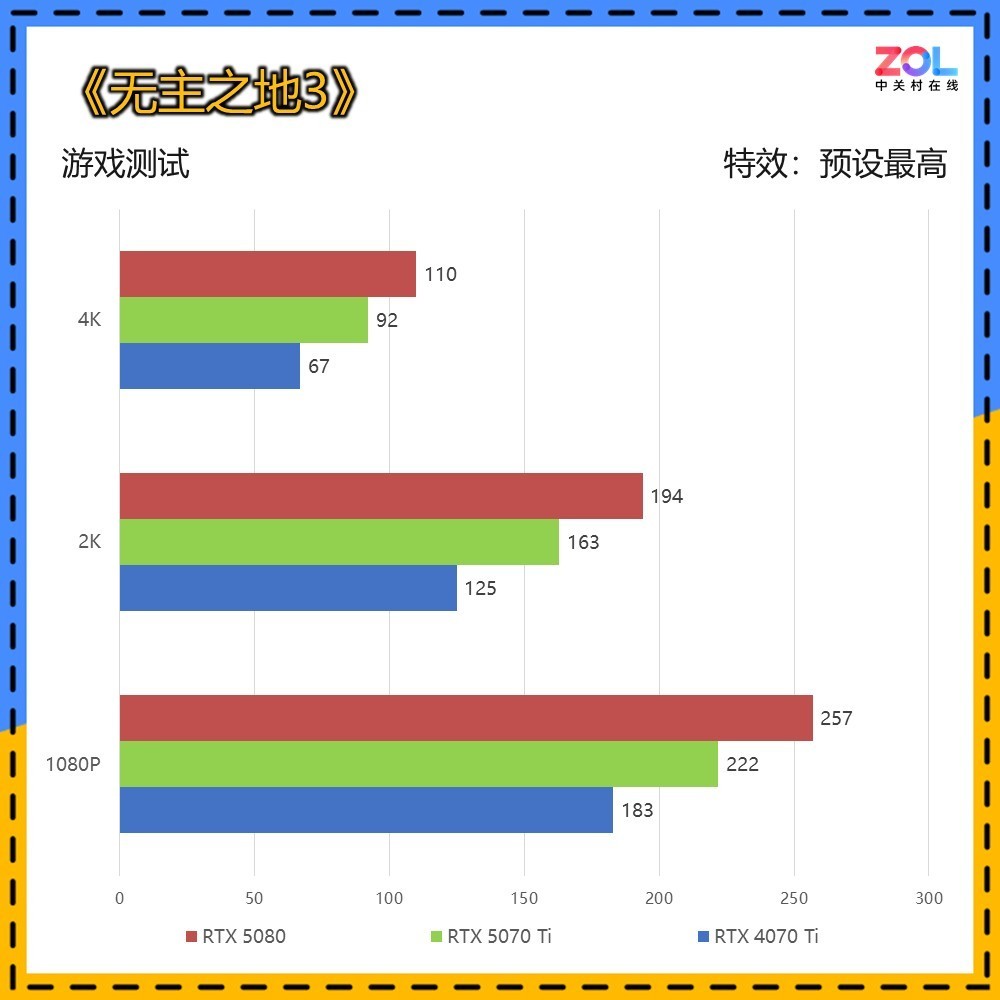
在《无主之地3》中,RTX 5070 Ti 16GB相比RTX 4070Ti的提升分别为:1080p提升21%;2K提升30%;4K提升37%,综合提升29%。在纯光栅化游戏帧数对比中,《无主之地3》比较能概括RTX 5070 Ti与RTX 4070 Ti的光栅化性能的综合差距。
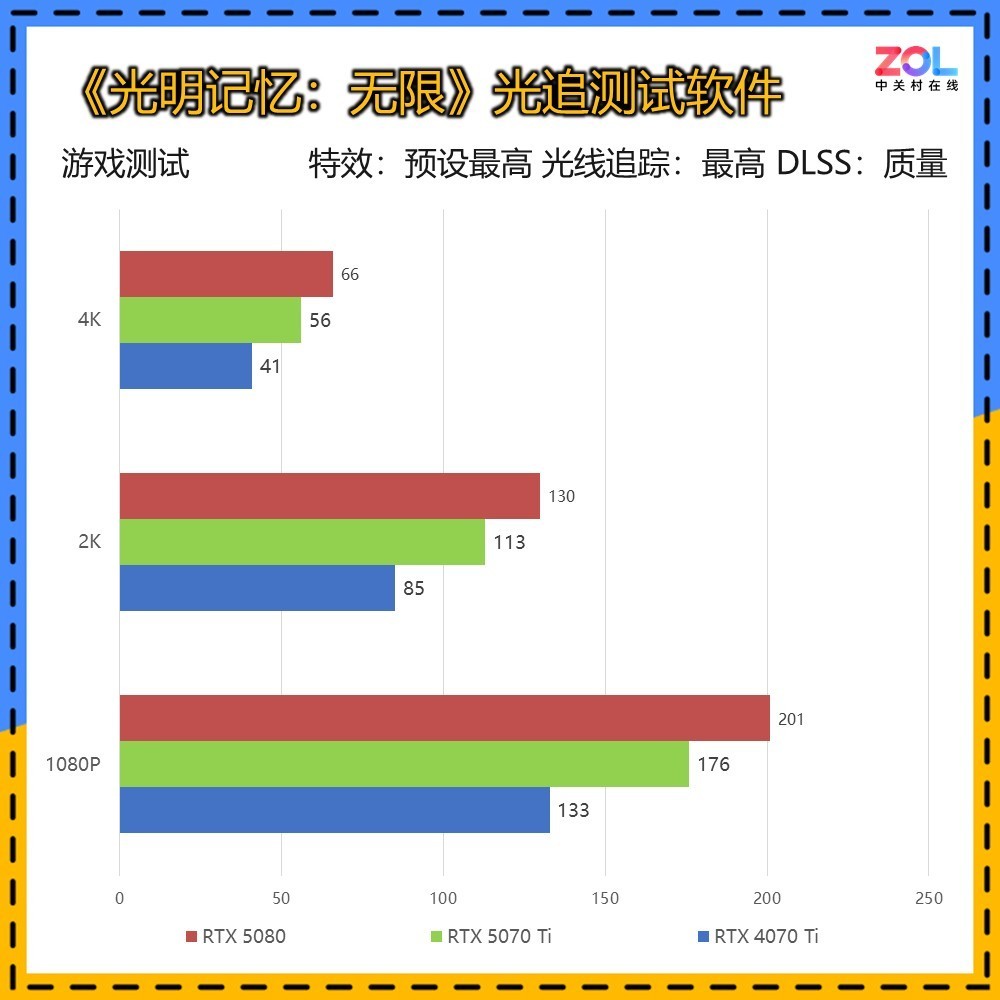
《光明记忆:无限》的光追测试软件是独立于游戏的测试工具,比游戏中用到的光线追踪技术更多,虽然游戏较老,但对于性能要求却非常高,本次测试条件为“RTX最高/DLSS质量”。
性能方面,RTX 5070 Ti 16GB相比RTX 4070 Ti的提升分别为:1080p提升32%;2K提升33%;4K提升37%,综合提升34%。
本代RTX 5070 Ti同样拥有16GB的显存,而且新架构对于内容创作软件同样有优化,下面我们分别测试了不同类别的专业软件,来看看实际效果。
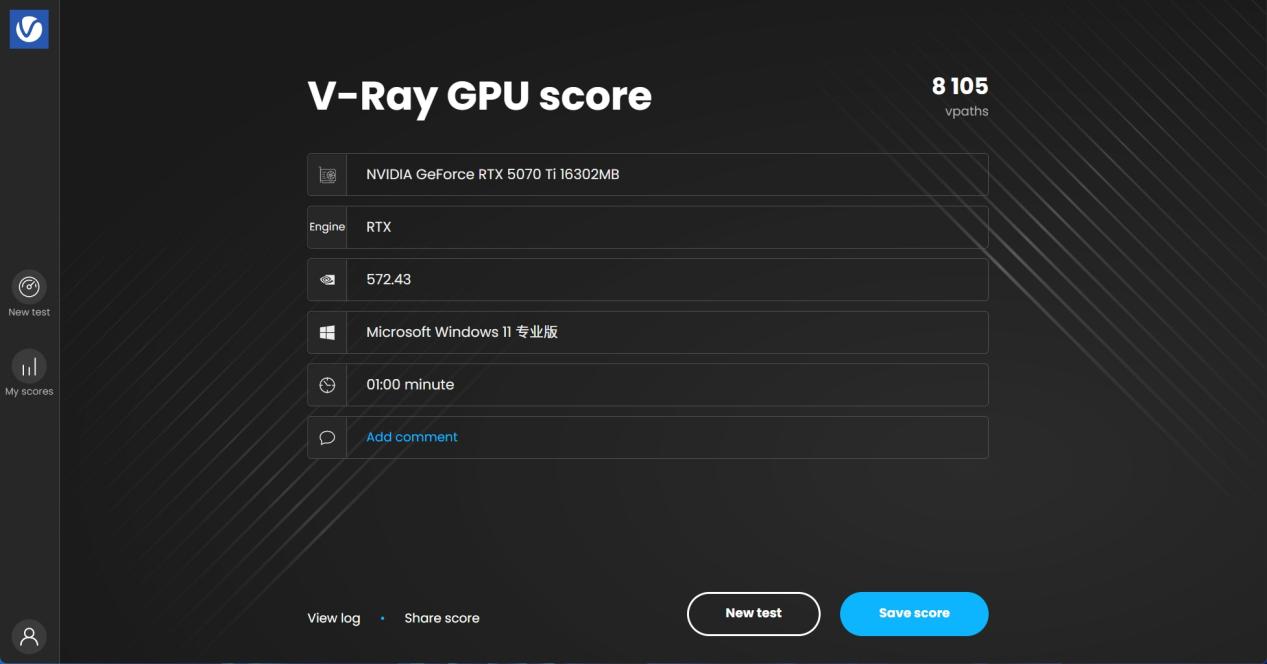
V-Ray6对于GPU的测试分为RTX与CUDA,这里主要看RTX成绩,其中RTX测试为8030分,相比RTX 4070 Ti(3024)首测时提升166%左右。更出色的架构加上更大的显存,让本代70级产品同样能够成为优秀的生产力工具。
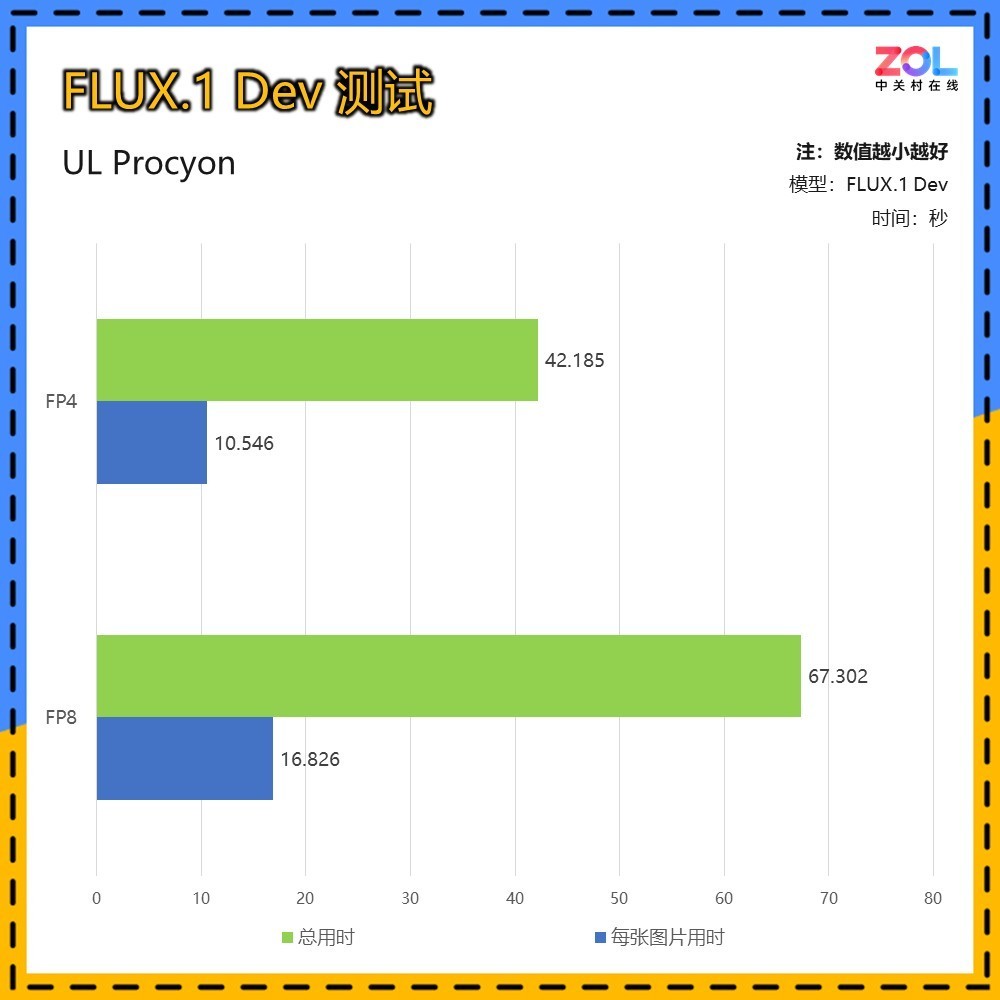
本次测试UL提供了FLUX.1Dev绘画模型的FP4测试,该模型在FP16上运行需要超过23GB的显存,而这意味着它只能支持每一代的旗舰级产品,例如RTX 4090、RTX 5090和H100这样的专业GPU来支持。相对来说,FP4只需要不到一半的显存,FP4使用NVIDIA Tensor RT提供的量化方法,几乎没有质量损失,显存消耗更小让更多80级和70级的显卡均能在本地运行。
Blackwell架构新的Tensor Core特性不仅让生成所需的显存显著减少,在生成时间也有大幅降低,平均4张图片即可节省25秒时间。


在结果对比中,FP8和FP4所生成的图片效果是相同的,在细节和图片精度上均有着良好表现。
NVIDIA Broadcast是一款用于直播或会议的AI软件,目前随着RTX 50系的发布,也进行了版本更新。
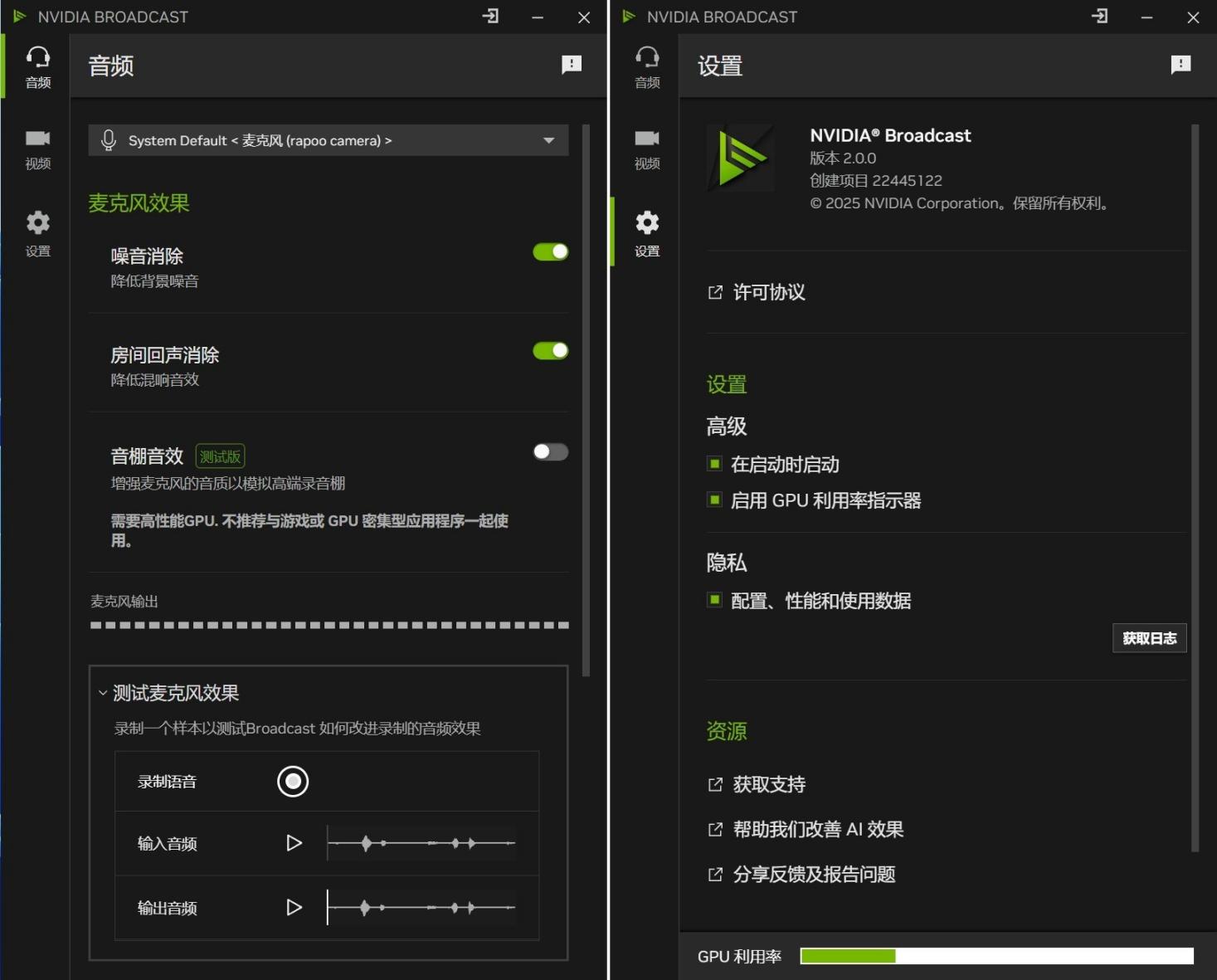
新版NVIDIA Broadcast界面更小巧,纵向布局也更方便视频直播中调节选项。
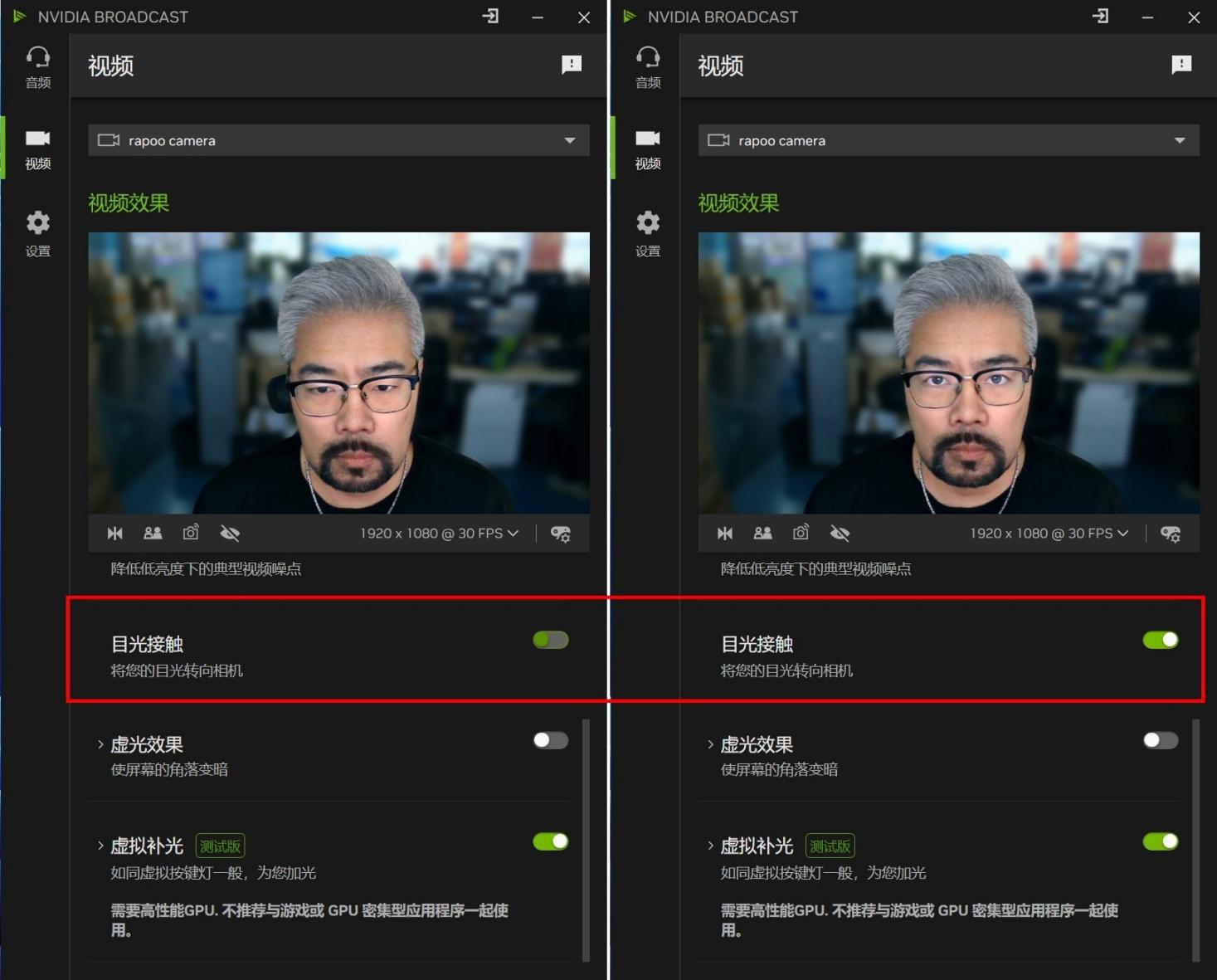
NVIDIA Broadcast一些经典效果更方便开启,其中目光接触功能非常适合远程会议,即便眼睛盯着屏幕,也能让参与人员时刻注意到你的眼睛,并且还有一定“大眼”效果。
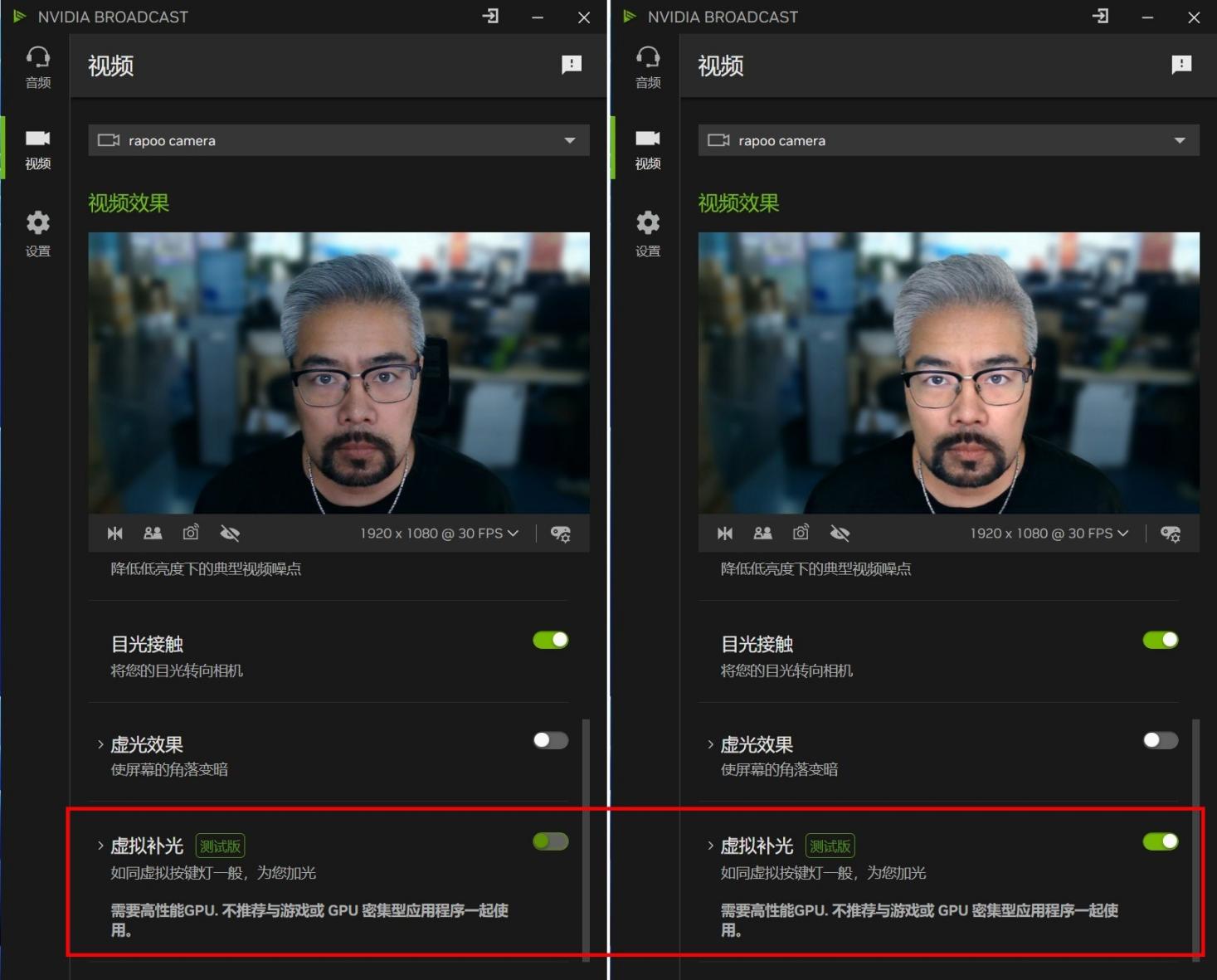
虚拟补光仍是测试版功能,它可以在光线较暗的情况下进行面部的AI补光,看你看起来仍然处于光线较好的环境中。
新版的NVIDIA app代替了原来的GFE软件,并且功能更强大,使用起来也更方便。最主要的是,它不用登陆了,即下即用。
从APP中强制开启DLSS 4的功能上面已有介绍,不过目前并不是所有游戏和软件均支持此功能。
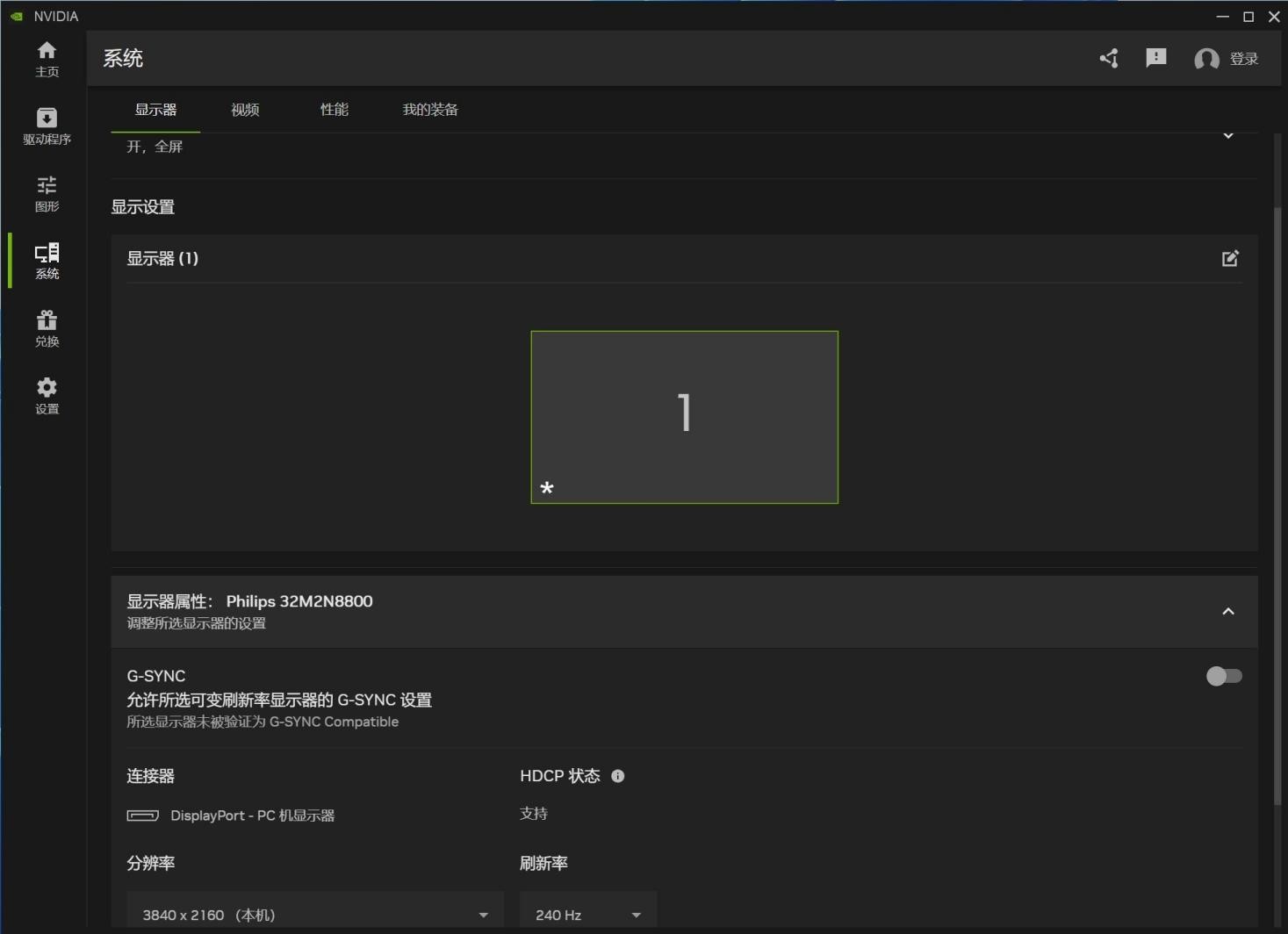
系统界面中则更多的是调试类功能,如显示器、视频、超频等。
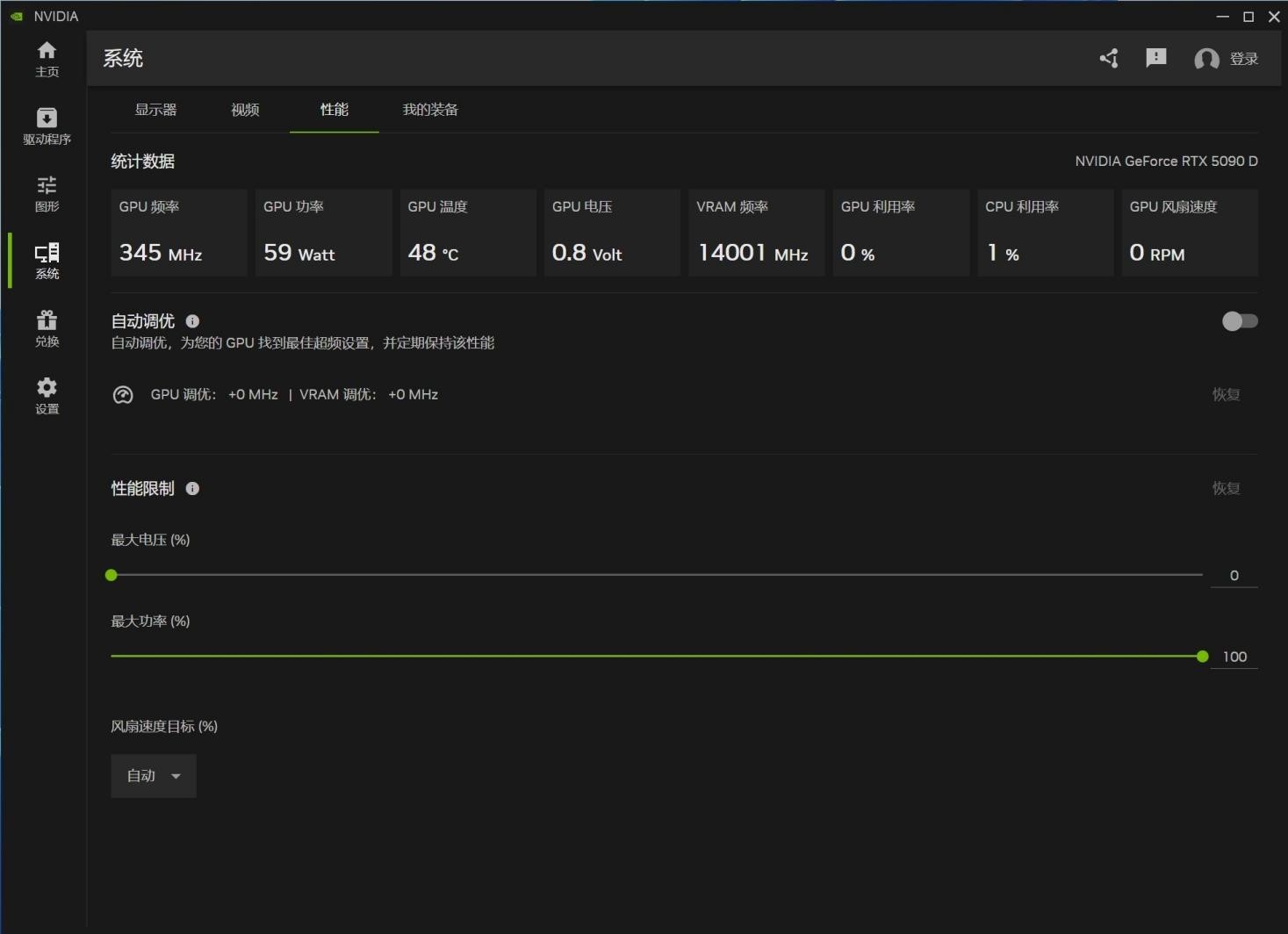
其中性能界面提供了较为详细的监控和超频选项,需要注意的是新手如果想尝试超频,尽量不要改变电压,这个选项轻则掉驱动,重则烧毁显卡。
另外玩家可放心大胆地使用NVIDIA app中的性能自动调优功能,经过NVIDIA反复验证过的参数都是在安全范围内,并且出现问题的话,这张卡仍然具备保修资格。
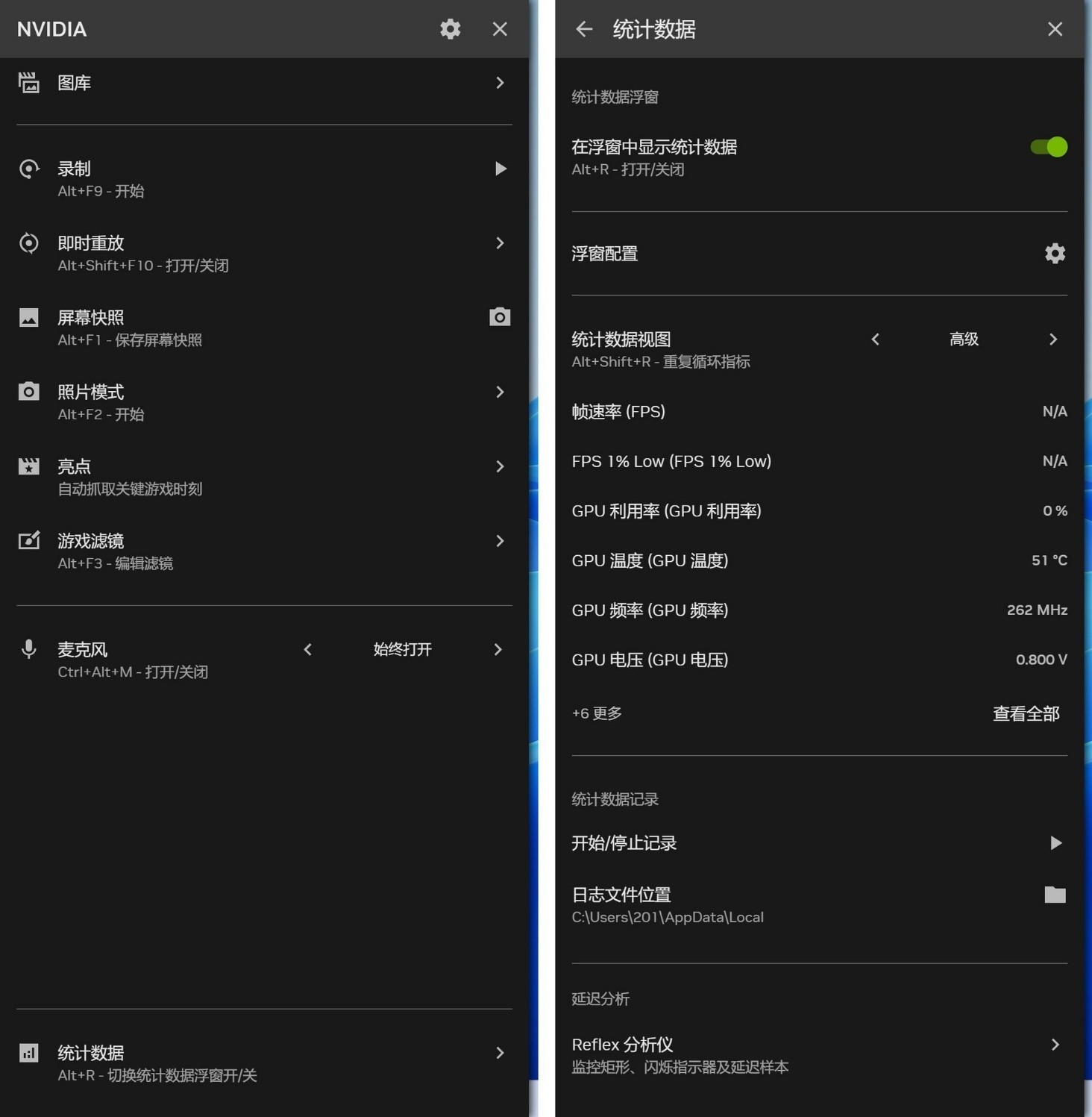
NVIDIA信息浮窗是游戏中很好的辅助工具,要开启此功能,需要在APP主界面的设置一栏中,开启按钮,之后按【ALT+Z】即可呼出边栏。
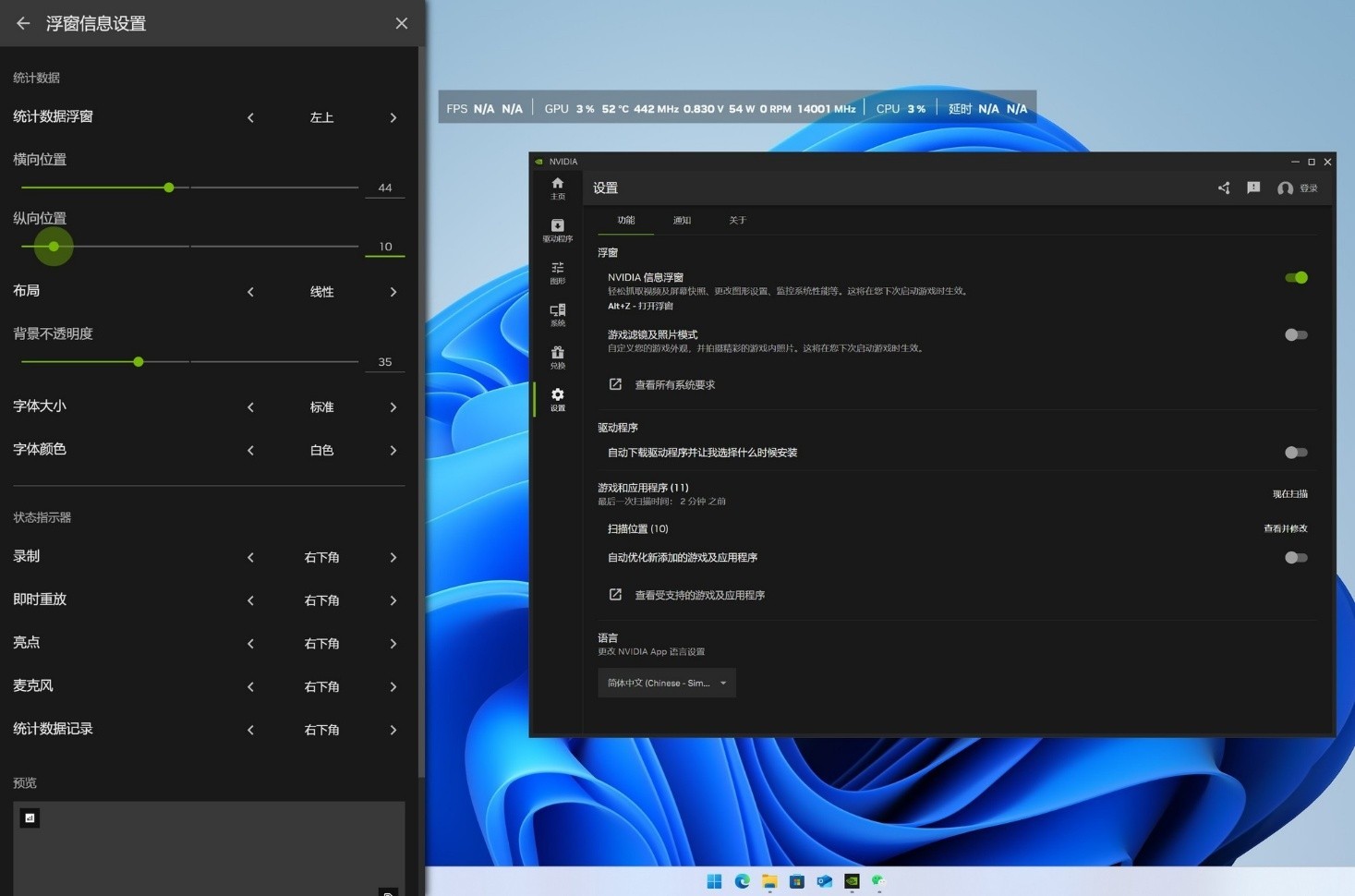
按【ALT+R】可呼出统计数据的浮窗,功能设置和自由度的调节也非常丰富,最主要的是相当简便。
功耗测试中,我们选择FurMark2软件进行拷机测试,并采用AIDA 64检测信息。
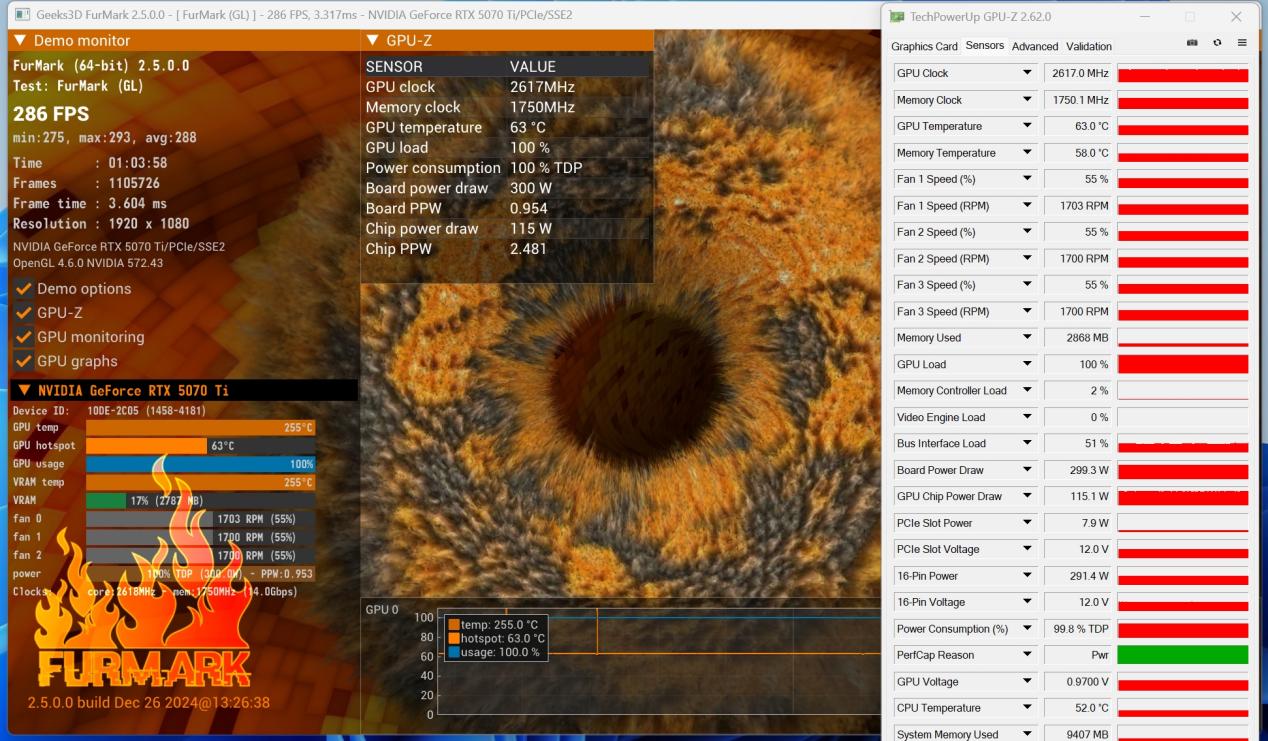
FurMark软件截至首测时,尚无法检测到GPU信息,部分温度识别有误。我们主要看GPUZ的信息。
RTX 5070 Ti 16GB在2小时左右的烤机测试中GPU温度为69℃;显存温度为60℃。另外可以看到在TDP 100%的满载情况下,整卡功耗为300W。
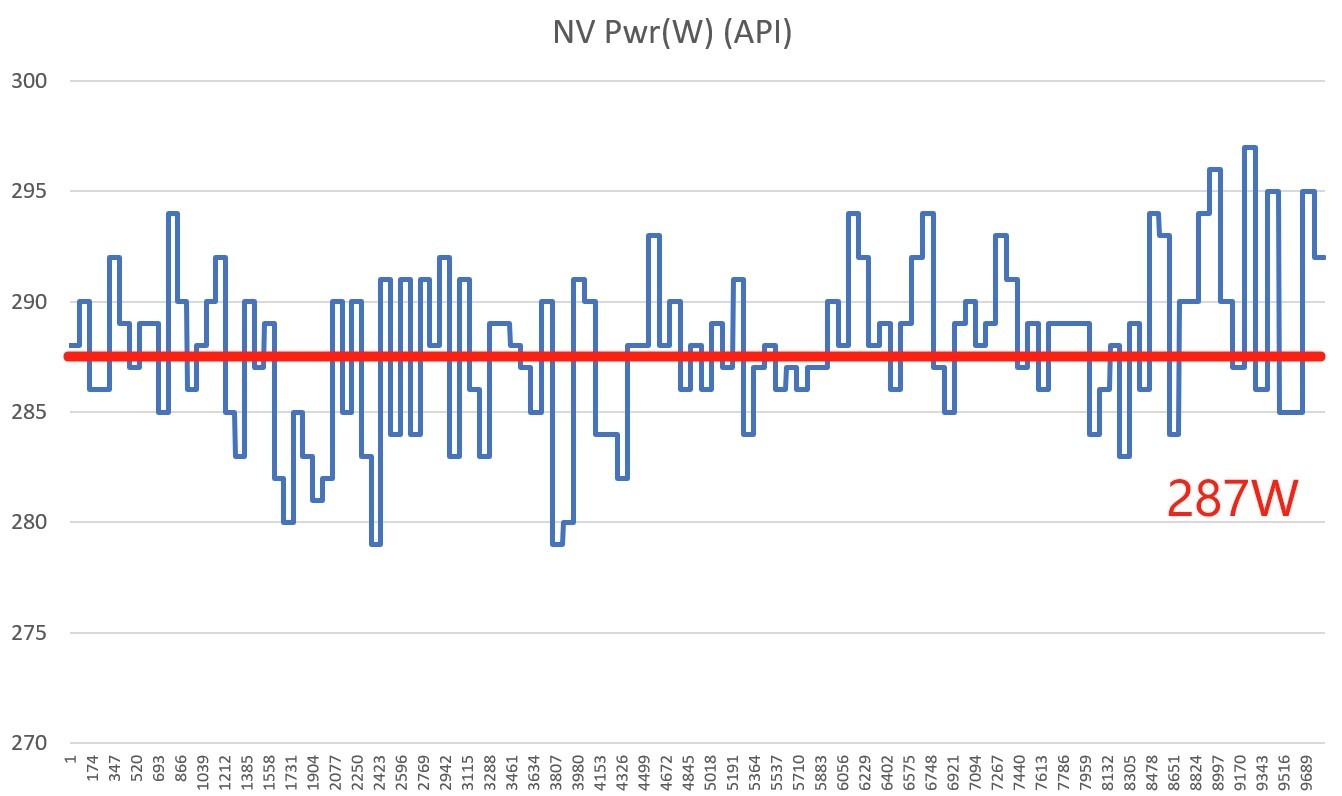
除了满载烤机,我们也实测了游戏中显卡的真实数据表现。测试选择《赛博朋克2077》,4K分辨率下光追超级画质,并开启DLSS 4 4X多帧生成,将显卡性能拉满。
可以看到RTX 5070 Ti 16GB的平均功耗为287W左右。
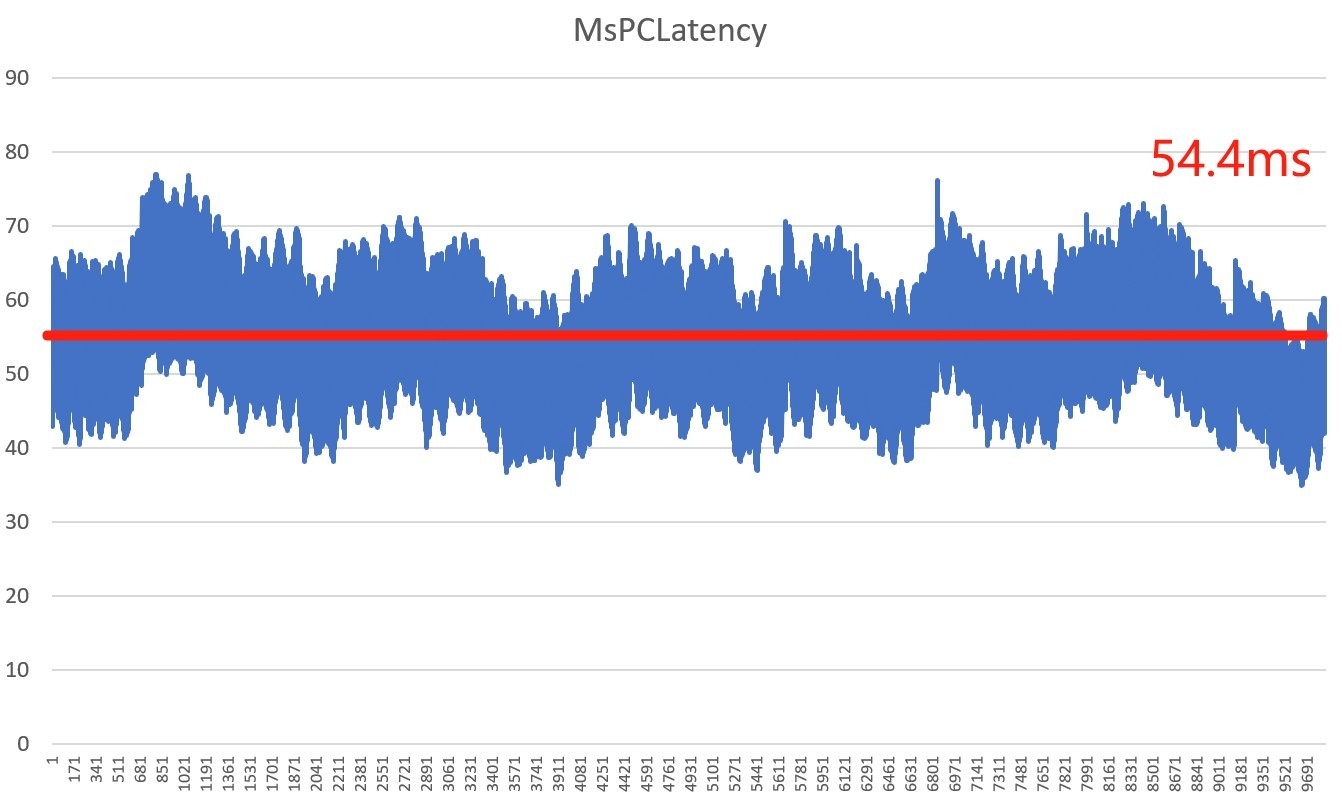
《赛博朋克2077》光追超级画质延迟
进行功耗检测的同时,我们也调出了延迟数据,在DLSS 4 4X多帧生成的环境下,游戏平均延迟为54.4ms左右。证明即便有多张AI生成帧参与到游戏中,我们依然能获得比较“跟手”的操作体验。
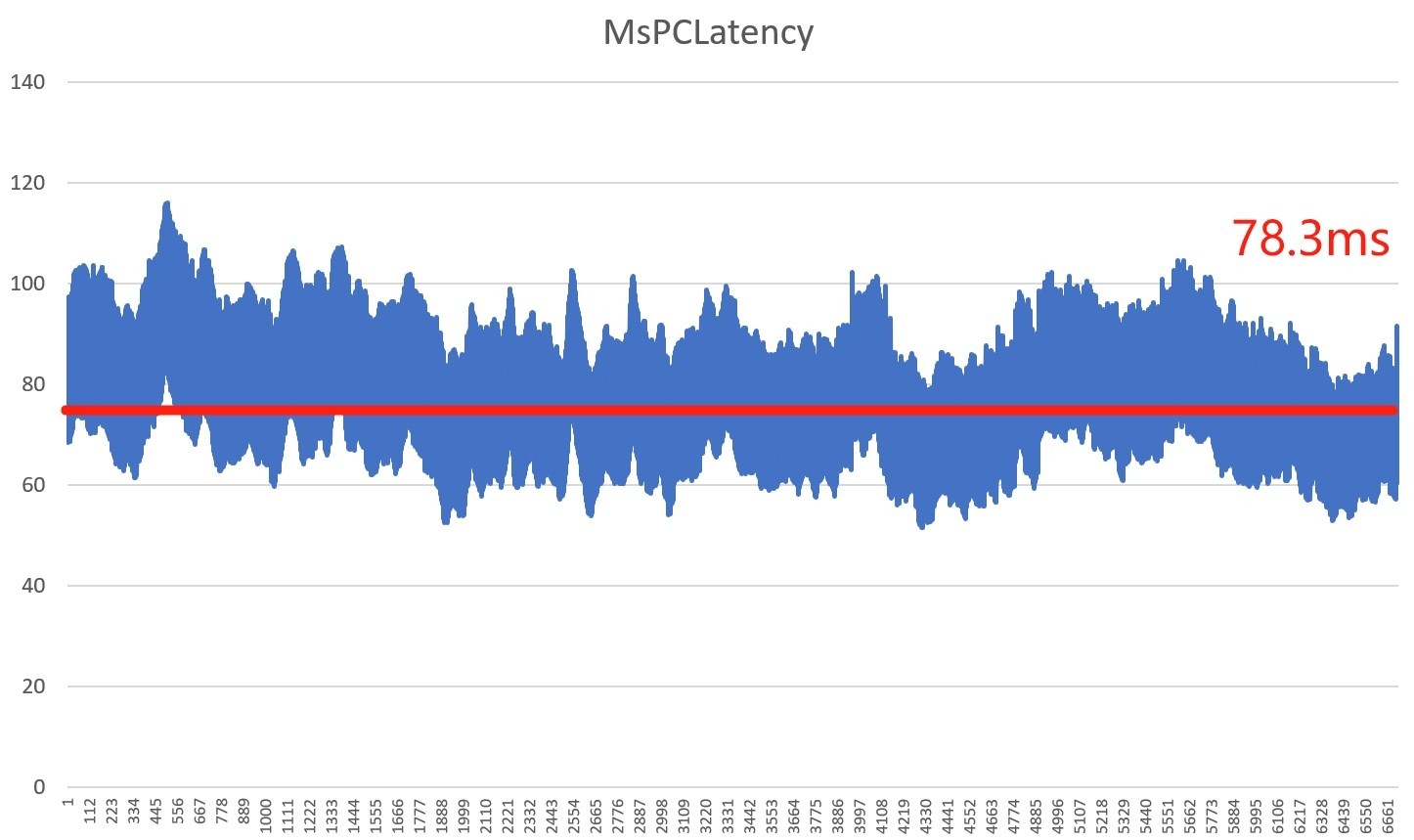
《赛博朋克2077》光追加速画质延迟
需要注意的是,多帧生成游戏延迟并不固定,与原始帧率息息相关,在《赛博朋克2077》游戏中,开启多帧生成时也会提示,建议帧率在60以上开启多帧生成。简单来说,虽然经过DLSS 4 4X加持能够达到108帧的成绩,但原始帧率过低,也会让延迟大幅增加。
技嘉GeForce RTX 5070 Ti GAMING OC 16G魔鹰显卡在性能测试中表现优异,不仅拥有出色的DX11和DX12性能,更在光追和DLSS 4技术上展现了强大实力。其独特的风之力散热系统和全尺寸金属背板确保了良好的散热效果和稳定性。此外,该显卡丰富的接口配置和电竞Gasket结构设计,满足了不同用户的需求。如果是预算有限的玩家,也可以考虑技嘉的风魔系列显卡,虽然作为,但魔鹰系列在性能上毫不含糊,也是不错的性价比选择。值得一提的是RTX 5070 Ti WINDFORCE OC SFF 16G风魔官方价格是6299元起步,性价比非常不错。
现代科技中融入复古情怀 vivo X200 Ultra红圈美图欣赏
续航小霸王颜值也越级 OPPO K12s美图欣赏
经典的“万里舷窗”设计,iQOO Z10 Turbo Pro图赏
REDMI Turbo 4 Pro图赏,2.5K价位段颜值做工的扛把子
荣耀X10拍照真实体验
担心孩子迷恋网络?
AI手机瞬间让你变成外国人
送腕表等好礼!9月17日ZOL&斗鱼30系显卡首发直播
华硕天选游戏笔记本
随身携带的素材库
体验SDA-2 DAC船解码耳放一体机
有限空间里的声音美学
最近还爱上了便携吸尘器
巫便携式CD机带你回到校园时代
这个设计果然有胆识
下载ZOL APP秒看最新热品
内容声明:1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违规信息,如您发现违规内容,请联系我们进行清除处理!
4、本文地址:http://www.2263.com.cn/article/49.html,复制请保留版权链接!
-

智能扫地机器人哪个牌子好?高性价比产品强烈推荐
-

易号网,挑“靓号”,让你省心省钱
-

“耕新视野,升级视界”带你回顾武汉线下体验会
-

戴睿V40Pro问世,英特尔独显初露锋芒
-
技嘉GeForceRTX5070TiGAMINGOC16G评测:游戏玩家的致胜选择_技嘉GeForceRTX5070TiGamingOC16G魔鹰_游戏硬件显卡
-

蓝宝石RX9070/RX9070XT显卡首测2K价格4K体验_游戏硬件显卡
-
DIY小技巧:如何判断50系显卡有芯片缺陷?_游戏硬件显卡
-

iGameGeForceRTX5070TiAdvancedOC16GB首测引力之环释放绝对性能_游戏硬件显卡
-

《黑神话》影神图实体版公布骂声一片_游戏硬件显卡
-

NVIDIA发布RTX50系显卡性能提升2倍以上!_游戏硬件显卡
-
2345链-2345自助链,2345网址目录,2345网址导航
-
易流链收录网-16自助链,16link网站流量联盟,一路链秒收录,站长网址之家,免费友情链接
-
66收录网 - 六六云链_自动秒收录_网址快速收录_百度收录_友情链接平台_免费收录网站_站长自助收录友情链接平台
-
2345网址导航-最好的网址导航(已创建19年07个月)最好的导航站!2345上网导航
-
瑞丽网 – 网聚世界潮流,设计你的时尚|rayli.com.cn
-
网易云音乐
-
星空影院
-
懒人导航网(85dh.cn)致力于打造百年网站-本站收录全网资源及各种网站
-
千川涨粉-专业抖音涨粉|千川投流涨粉源头|抖音有效粉
-
下载梨翱联网-优质且充满趣味的知识交流平台
-
冠旭宠物网
-
天恩名站 - 行业推广网站分类目录信息发布平台
出海东盟(泰国)博览会今夏6月为“中国企业出海”抢摊新赛道、新风口
记者获悉,由深圳市物流与供应链管理协会、深圳市跨境电商供应链协会、连博责任有限公司(新加坡)连同美洲供应链协会(美国)、欧亚供应链协会(荷兰)举办的出海东盟(泰国)博览会将于2025年6月11日至13日在泰国曼谷诗丽吉王后国家会议中心举行。&nb
2025-05-31 22:13:03
“融合创新·科技赋能”绵广遂三地携手举办科技资源对接活动
为贯彻落实党的二十大会议精神,积极推进成渝双城经济圈建设,10月31日,由西南科技大学、绵阳市科学技术局、广元市科学技术局、遂宁市科学技术局主办,绵阳市涪城区人民政府、涪城区科学技术局承办,四川省军民融合研究院协办的“创新金三角·智汇科技城”系列活动第五场“融合创新·科技赋能”川北专场活动在绵阳举办。资
2025-05-31 21:39:13
以“莓”为媒,调研乡村振兴发展新路子:车辆工程学院走进南川大观镇调研嘉蓝悦霖农业公司
7月8日上午,重庆理工大学车辆工程学院“绿色行动,大美大观”乡村振兴促进团深入南川大观镇调研了嘉蓝悦霖农业公司。此次行动,作为车辆工程学院“三下乡”活动的重要一环,为加强城乡交流,推动乡村振兴,深入了解当地乡村产业和文化,促进乡村经济的蓬勃发展,同学们深入企业生产一线,实地调研了大观镇乡村产业欣欣向荣
2025-05-31 21:17:02
成都舞东风超市违规宣传后又欺诈游客
近日,四川日报“问政四川”栏目有外地游客投入称:成都舞东风超市欺诈游客。具体投诉内容为:本人出差5月11日出差到成都入住美城悦荣府小区在小区门口舞东风超市选购纸巾纸巾标价32元后结账收银员告知会员价32非会员52元一袋纸巾差距20元20/32=0.625上浮了百分之六十二后
2025-05-31 21:02:26
新华社公布禁用词及规范用语
特别说明新华社总编室组织国内部、国际部、对外部、新闻研究所搜集整理了近年来各编辑部规定的禁用词,编成此次公布的第一批禁用词、规范用语。版权归新华社所有。一、社会生活类的禁用词1.对有身体伤疾的人士不使用“残废人”“独眼龙”“瞎子”“聋子”
2025-05-03 22:53:14
818好物精选,高性价比、高性能投影仪哪里购?818买当贝投影就对了
一年一度的818又来了,相比很多人在选购上又犯起了选择困难症,难点不仅仅来自于对产品的认知,还有对数学能力的考验,否则,一不小心就在计算优惠上吃了“数学不好”的亏。以数码产品类的投影仪为例,随着家用投影仪逐渐被大家所认知,越来越多的人有了替换智能电
2025-05-03 22:32:16
新政速递丨再见,985、211!教育部已官宣!
在很长一段时间里高考生和家长、老师心目中好大学的标准就是“985”和“211”也有很多考生和家长在问:现在是否还保留985、211工程高校的称呼?985、211工程高校和“双一流”建设高校到底是什么关系?最近,教育部对此问题作出了官方正式回复↓
2025-05-03 21:46:26
筑牢安全防线四川雅江县开展施工企业综合督导检查
11月23日,雅江县委常委、常务副县长降拥尼玛率队深入雅江县境内的G318沿线施工企业及重点林区防火卡点,针对安全生产、森林草原防灭火、生态环境保护等关键领域,开展了一场全面而深入的综合督导检查。此次行动得到了县应急管理局负责人的全程陪同。督导检查现场督导组一行采取暗访抽查的方式,先后走访了格西沟森林防
2025-04-25 09:30:29
以案说险丨虚拟投资养老?拒当老龄“韭菜”-大家人寿四川分公司2022年金融联合教育宣传活动
【风险提示】以案说险丨虚拟投资养老?拒当老龄“韭菜”-大家人寿四川分公司2022年金融联合教育宣传活动全民理财时代的到来,推动了金融行业的蓬勃发展,不少“虚拟”投资产品也混入其中,忽悠着一波又一波老年人送上“养老小金库”。大家人寿保险股份有限公司四川分公司带您一起以案说险。案例重现张阿姨退休不久,偶然机会
2025-04-25 09:00:04
扫地机器人哪个牌子好?十大排名谁更适合上班族?
仁者见仁智者见智,因为认知差异和需求的不同,一千个人眼里有一千个哈姆雷特,不同的扫地机器人用户更是对十大排名中的各品牌褒贬不一,扫地机器人到底哪个牌子好?行业十大排名中谁才更适合上班族用户选购呢?1.斐纳TOMEFON斐纳TOMEFON是在德国销量第一的扫地机器人品牌,精细的全局规划效果让用户能轻松掌控家庭清洁的一
2025-04-25 08:49:38
颜可可:惊艳亮相,优雅舞者气质令人心动!
在这个充满机遇与挑战的时代,有一位Height/170Weight/54BWH:78-65-87有着一双修长的腿,整个身姿高挑而匀称,不需要太多的装饰,就可以轻易地吸引人们目光的女孩,她就是——颜可可。摩羯座23岁的她,正值青春年华,犹如一朵盛开的鲜花,散发着迷人的芬芳,也拥有着模特般的自信与优雅,聪明、坚韧、有
2025-04-25 08:47:46